|
Mirror
and Glass Detection/Segmentation
|
|
In this project, we are
developing techniques for mirror and glass detection/segmentation. While a mirror
is a reflective surface that reflects the scene in front of it, glass is a transparent
surface that transmits the scene from the back side and often also reflects
the scene in front of it too. In general, both mirrors and glass do not have
their own visual appearances. They only reflect/transmit the appearances of
their surroundings.
As mirrors and glass do
not have their own appearances, it is not straightforward to develop
automatic algorithms to detect and segment them. However, as they appear
everywhere in our daily life, it can be problematic if we are not able to
detect them reliably. For example, a vision-based depth sensor may falsely
estimate the depth of a piece of mirror/glass as the depth of the objects
inside it, a robot may not be aware of the presence of a mirror/glass wall,
and a drone may collide into a high rise (noted that most high rises are
covered by glass these days).
To the best of our
knowledge, my team is the first to develop computational models for automatic
detection and segmentation of mirror and transparent glass surfaces. Although
there have been some works that investigate the detection of transparent
glass objects, these methods mainly focus on detecting wine glass and small
glass objects, which have some special visual properties that can be used for
detection. Unlike these works, we are more interested in detecting general
glass surfaces that may not possess any special properties of their own.
We are also interested
in exploring the application of our mirror/glass detection methods in
autonomous navigation.
|
|
Multi-Semantic Modeling for
Glass Surface Detection in the Wild (Oral
Presentation) [paper]
[suppl]
[model]
Qianyu
Cheng, Huankang Guan, and Rynson Lau
Proc. AAAI, Jan. 2026
|
|
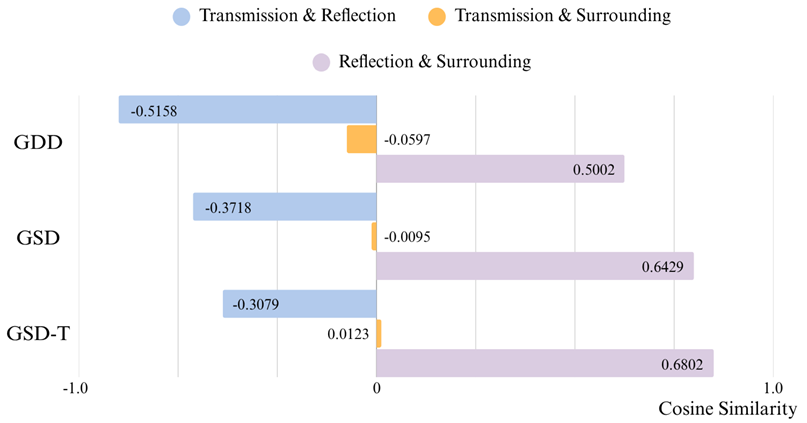
Semantic Similarity Analysis. We quantify
similarity among transmission semantics (semantics of glass transmitted
content), reflection semantics (semantics of glass reflected content),
and surrounding semantics (semantics of non-glass regions) based on
CLIP, evaluated on GDD (top), GSD (middle) and DSD-T (bottom) datasets.
Results consistently indicate a higher similarity between reflection and
surrounding semantics, while both differ from transmission semantics.
(Positive numbers indicate similarity scores, and negative numbers
indicate dissimilarity scores.)
|
|
|
Input-Output: Given an input image,
our network outputs a binary mask that indicates where the glass surfaces
are.
Abstract. Glass surfaces
challenge object detection models as they mix the transmitted background
with the reflected surrounding, creating confusing visual patterns.
Previous methods relying on low-level cues (e.g., reflections and
boundaries) or surrounding semantics are often unreliable in complex real-world
scenarios. A glass image inherently comprises three distinct semantic
components: semantics of the transmitted content, semantics of the
reflected content, and semantics of the surrounding content. In this
work, we observe that there is a relationship among these three types of
semantics, where reflection semantics closely resembles surrounding
semantics, while these two types of semantics tend to be different from
the transmission semantics. For example, when on a street, we may see
into a cafeteria through a glass wall, intermixed with reflection of the
street, while the glass is surrounded by other street contents like shops
and pedestrians, thereby creating a unique multi-semantic signature.
Based on this observation, we propose the Multi-Semantic Net, MSNet, which
identifies transmission, reflection, and surrounding semantics from glass
images and exploits their relationships for glass surface detection.
MSNet consists of two novel modules: (1) A Semantic Decomposition Module
(SDM) containing Dual-Semantics Extraction Block to extract original
image and reflection semantics and Semantic Elimination Block to
progressively derive transmission and surrounding semantics, and (2) An
Adaptive Semantic Fusion Module (ASFM) to fuse these semantic components
and adaptively learn their relationships to handle varying reflection
conditions. Extensive experiments demonstrate that MSNet surpasses SOTA methods
on public glass detection benchmarks.
|
|
Video Mirror
Detection with the Motion-in-Depth Cue (Oral
Presentation) [paper]
[suppl]
[model]
Alex Warren,
Ke Xu, Xin Tian, Gary Tam, Benjamin Wah, and Rynson Lau
Proc. AAAI, Jan. 2026
|
|
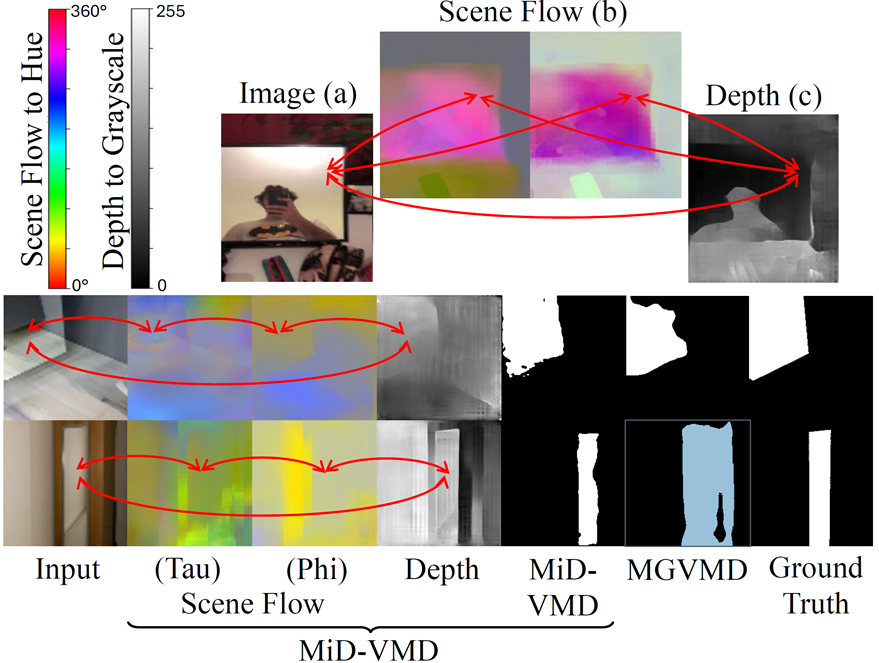
The SOTA video mirror detection MGVMD (Warren et
al. 2024) primary models 2D motion, which fails in featureless or
weak-motion regions (lower example, 6th column). The upper example
illustrates three complementary cues: RGB appearance (a), contrastive
3D motion (b), and depth (c). These complementary cues, shown across columns
1 4 in the lower example, correlate strongly inside and outside mirrors
and provide greater robustness than 2D motion alone. This observation
aligns with human MiD perception, motivating our MiD-inspired approach.
|
|
|
Input-Output: Given an input
video, our network outputs a sequence of binary masks indicating where
the mirrors are in each frame.
Abstract. Detecting mirror
regions in RGB videos is essential for scene understanding in
applications such as scene reconstruction and robotic navigation.
Existing video mirror detectors typically rely on cues like
inside-outside mirror correspondences and 2D motion inconsistencies.
However, these methods often yield noisy or incomplete predictions when
confronted with complex real-world video scenes, especially in areas with
occlusion or limited visual features and motions. We observe that human
perceive and navigate 3D occluded environments with remarkable ease,
owing to Motion-in-Depth (MiD) perception. MiD integrates information
from visual appearance (image colors and textures), the way objects move around
us in 3D space (3D motions), and their relative distance from us (depth)
to determine if something is approaching or receding and to support
navigation. Motivated by this neuroscience mechanism, we introduce
MiD-VMD, the first approach to explicitly model MiD for video mirror
detection. MiD-VMD jointly utilizes contrastive 3D motion, depth, and image
features through two novel modules based on a combinational QKV
transformer architecture. The Motion-in-Depth Attention Learning (MiD-AL)
module captures complementary relationships across these modalities with
combinatorial attention and enforces a compact encoding to represent global
3D transformations, resulting in more accurate mirror detection and
reduced motion artifacts. The Motion-in-Depth Boundary Detection (MiD-BD)
module further sharpens mirror boundaries by leveraging cross-modal
attention on 3D motion and depth features. Extensive experiments show
that MiD-VMD outperforms current SOTAs.
|
|
|
Leveraging RGB-D Data with
Cross-Modal Context Mining for Glass Surface Detection [paper]
[suppl]
[model] [dataset]
Jiaying Lin,
Yuen-Hei Yeung, Shuquan Ye, and Rynson Lau
Proc. AAAI, Feb. 2025
|
|

Advantages of detecting glass surfaces with
RGBD images. These examples show that the depth map can provide a
strong cue for glass surface detection. State-of-the-art methods,
GSDNet (Lin, He, and Lau 2021) and EBLNet (He et al. 2021), relying
only on input RGB images are not able to correctly separate the glass
surfaces from the background. Through learning the cross-modal contexts
and the correlation between depth-missing regions and glass surface
regions, our proposed model can detect the glass surfaces accurately in
all three challenging scenes. Note that red regions in the depth images
represent missing depths.
|
|
|
Input-Output: Given an input RGB-D
image, our network outputs a binary mask that indicates where the glass
surfaces are.
Abstract. Glass surfaces
are becoming increasingly ubiquitous as modern buildings tend to use a
lot of glass panels. This, however, poses substantial challenges to the
operations of autonomous systems such as robots, self-driving cars, and
drones, as these glass panels can become transparent obstacles to
navigation. Existing works attempt to exploit various cues, including glass
boundary context or reflections, as priors. However, they are all based
on input RGB images. We observe that the transmission of 3D depth sensor
light through glass surfaces often produces blank regions in the depth
maps, which can offer additional insights to complement the RGB image
features for glass surface detection. In this work, we first propose a
large-scale RGB-D glass surface detection dataset, RGB-D GSD, for
rigorous experiments and future research. It contains 3,009 images,
paired with precise annotations, offering a wide range of real-world
RGB-D glass surface categories. We then propose a novel glass surface
detection framework combining RGB and depth information, with two novel
modules: a cross-modal context mining (CCM) module to adaptively learn
individual and mutual context features from RGB and depth information,
and a depth-missing aware attention (DAA) module to explicitly exploit
spatial locations where missing depths occur to help detect the presence
of glass surfaces. Experimental results show that our proposed model outperforms
state-of-the-art methods.
|
|
|
GhostingNet: a Novel Approach
for Glass Surface Detection with Ghosting Cues [paper]
[model
and dataset]
Tao Yan,
Jiahui Gao, Ke Xu, Xiangjie Zhu, Hao Huang, Helong Li, Benjamin Wah, and
Rynson Lau
IEEE Trans. on
Pattern Analysis and Machine Intelligence, 47(1):323-337, Jan. 2025
|
|
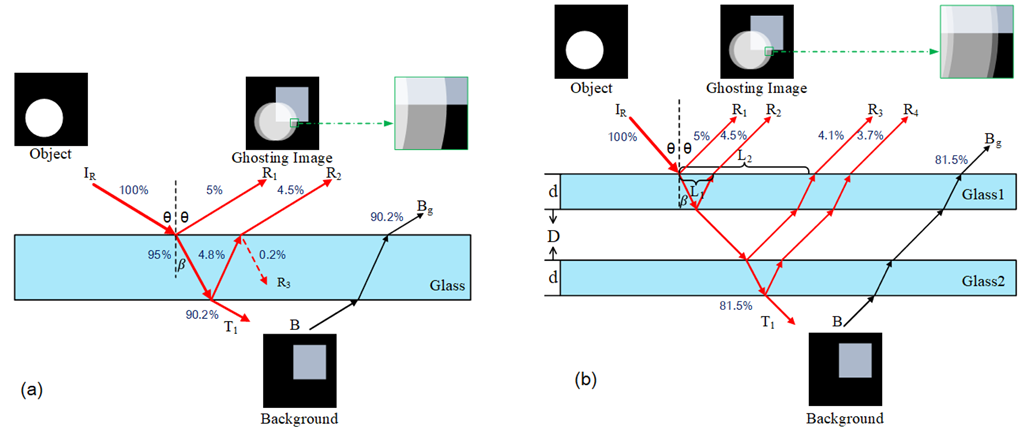
The idea of our work is based on detecting
more than one reflection produced by glass surfaces, for glass surface
detection. This figure demonstrates our ghosting image formation model
for two types of glass surfaces, (a) single-glazing, and (b)
double-glazing. Here, we show the approximate energy distribution as a
ray hits each contact surface, assuming that the reflection coefficient
and the transmission coefficient are 5% and 95%, respectively, of the incident
energy. In each diagram, we assume that the viewer is located at the
top of it looking down. The viewer would see the reflections (or
ghosting effects) of the object that is on the same side as the viewer,
i.e., the circular object.
|
|
|
Input-Output: Given an input image,
our network outputs a binary mask that indicates where the glass surfaces
are.
Abstract. Ghosting effects
typically appear on glass surfaces, as each piece of glass has two
contact surfaces causing two slightly offset layers of reflections. In
this paper, we propose to take advantage of this intrinsic property of
glass surfaces and apply it to glass surface detection, with two main
technical novelties. First, we formulate a ghosting image formation model
to describe the intensity and spatial relations among the main
reflections and the background transmission within the glass region.
Based on this model, we construct a new Glass Surface Ghosting Dataset
(GSGD) to facilitate glass surface detection, with ∼3.7K glass images
and corresponding ghosting masks and glass surface masks. Second, we
propose a novel method, called GhostingNet, for glass surface detection.
Our method consists of a Ghosting Effects Detection (GED) module and a
Glass Surface Detection (GSD) module. The key component of our GED module
is a novel Double Reflection Estimation (DRE) block that models the
spatial offsets of reflection layers for ghosting effect detection. The
detected ghosting effects are then used to guide the GSD module for glass
surface detection. Extensive experiments demonstrate that our method
outperforms the state-of-the-art methods.
|
|
|
|
Effective Video Mirror
Detection with Inconsistent Motion Cues [paper] [suppl] [model] [dataset]
Alex Warren, Ke
Xu, Jiaying Lin, Gary Tam, and Rynson Lau
Proc. CVPR, June 2024
|
|

We propose to model motion inconsistency as a
cue for mirror detection. The 1st column shows the inconsistent motions (depicted
with arrows). The locations of these cues align well with the mirror
regions. The 2nd column shows the optical flow computed between frame N
(3rd column), and frame N-1 from respective videos in our new dataset.
Our method (5th column) predicts more reliable and consistent mirror
regions, outperforming VMDNet (4th column). The 6th column is the ground
truth.
|
|
|
Input-Output: Given an input
video, our network outputs a sequence of binary masks indicating where the mirrors
are in each frame.
Abstract. Image-based mirror
detection has recently undergone rapid research due to its significance in
applications such as robotic navigation, semantic segmentation and scene
reconstruction. Recently, VMD-Net was proposed as the first video mirror
detection technique, by modeling dual correspondences between the inside
and outside of the mirror both spatially and temporally. However, this
approach is not reliable, as correspondences can occur completely inside or
outside of the mirrors. In addition, the proposed dataset VMD-D contains
many small mirrors, limiting its applicability to real-world scenarios. To
address these problems, we developed a more challenging dataset that
includes mirrors of various shapes and sizes at different locations of the
frames, providing a better reflection of real-world scenarios. Next, we
observed that the motions between the inside and outside of the mirror are
often inconsistent. For instance, when moving in front of a mirror, the
motion inside the mirror is often much smaller than the motion outside due
to increased depth perception. With these observations, we propose modeling
inconsistent motion cues to detect mirrors, and a new network with two novel
modules. The Motion Attention Module (MAM) explicitly models inconsistent
motions around mirrors via optical flow, and the Motion-Guided Edge
Detection Module (MEDM) uses motions to guide mirror edge feature learning.
Experimental results on our proposed dataset show that our method
outperforms state-of-the-arts.
|
|
|
Multi-view Dynamic Reflection
Prior for Video Glass Surface Detection [paper] [suppl]
[model] [dataset]
Fang Liu,
Yuhao Liu, Jiaying Lin, Ke Xu, and Rynson Lau
Proc. AAAI, Feb. 2024
|
|
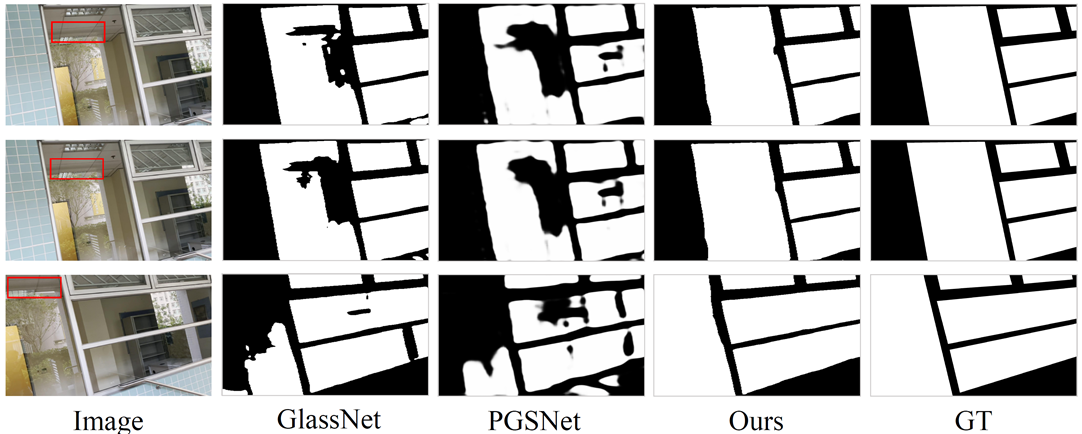
Comparison of our VGSD-Net with the
state-of-the-art image-based glass detection methods, GlassNet (Lin, He,
and Lau 2021) and PGSNet (Yu et al. 2022). They produce
temporal-inconsistent results when applied to the VGSD task, as they do
not exploit any temporal information. In contrast, our method learns
dynamic reflection cues from the video, yielding more accurate and robust
results.
|
|
|
Input-Output: Given an input
video, our network outputs a sequence of binary masks indicating where the
glass surfaces are in each frame.
Abstract. Recent research has
shown significant interest in image-based glass surface detection (GSD).
However, detecting glass surfaces in dynamic scenes remains largely
unexplored due to the lack of a high-quality dataset and an effective video
glass surface detection (VGSD) method. In this paper, we propose the first
VGSD approach. Our key observation is that reflections frequently appear on
glass surfaces, but they change dynamically as the camera moves. Based on
this observation, we propose to offset the excessive dependence on a single
uncertainty reflection via joint modeling of temporal and spatial
reflection cues. To this end, we propose the VGSD-Net with two novel
modules: a Location-aware Reflection Extraction (LRE) module and a
Context-enhanced Reflection Integration (CRI) module, for the
position-aware reflection feature extraction and the spatial-temporal
reflection cues integration, respectively. We have also created the first
large-scale video glass surface dataset (VGSD-D), consisting of 19,166
image frames with accurately-annotated glass masks extracted from 297
videos. Extensive experiments demonstrate that VGSD-Net outperforms
state-of-the-art approaches adapted from related fields.
|
|
|
ZOOM: Learning Video Mirror
Detection with Extremely-Weak Supervision [paper] [suppl] [model]
[dataset]
Ke Xu, Tsun Wai Siu, and Rynson Lau
Proc. AAAI, Feb. 2024
|
|

|
Input
|
SATNet
|
HetNet
|
VMDNet
|
Ours
|
GT
|
We propose ZOOM, which learns to detect mirrors with
extremely weak supervision, i.e., the zero-one mirror indicators. The key
insight of ZOOM is to model the similarity (blue
arrow) and contrast (red arrows) in
temporal variations for mirror detection. It achieves promising results against
fully-supervised mirror detectors.
|
|
|
Input-Output: Given an input video, our network
outputs a sequence of binary masks indicating where the mirrors are in each
frame.
Abstract. Mirror detection is
an active research topic in computer vision. However, all existing mirror
detectors learn mirror representations from large-scale pixel-wise datasets,
which are tedious and expensive to obtain. Although weakly-supervised learning
has been widely explored in related topics, we note that popular weak
supervision signals (e.g., bounding boxes, scribbles, points) still require
some efforts from the user to locate the target objects, with a strong
assumption that the images to annotate always contain the target objects.
Such an assumption may result in the over-segmentation of mirrors. Our key
idea of this work is that the existence of mirrors over a time period may
serve as a weak supervision to train a mirror detector, for two reasons.
First, if a network can predict the existence of mirrors, it can essentially
locate the mirrors. Second, we observe that the reflected contents of a
mirror tend to be similar to those in adjacent frames, but exhibit
considerable contrast to regions in far-away frames (e.g., non-mirror
frames). In this paper, we propose ZOOM, the first method to learn robust
mirror representations from extremely-weak annotations of per-frame ZerO-One
Mirror indicators in videos. The key insight of ZOOM is to model the
similarity and contrast (between mirror and non-mirror regions) in temporal
variations to locate and segment the mirrors. To this end, we propose a novel
fusion strategy to leverage temporal consistency information for mirror
localization, and a novel temporal similarity-contrast modeling module for mirror
segmentation.We construct a new video mirror dataset for training and
evaluation. Experimental results under new and standard metrics show that
ZOOM performs favorably against existing fully-supervised mirror detection
methods.
|
|
Self-supervised Pre-training for
Mirror Detection [paper] [model]
Jiaying Lin and Rynson Lau
Proc. IEEE ICCV, Oct. 2023
|
|

State-of-the-art mirror detection methods [37, 30]
are based on costly supervised ImageNet pre-training. They may fail even in
obvious cases, e.g., (a) when the mirror clearly reflects a real object
outside of the mirror. (b) and (c) are MirrorNet [37] and VCNet [30],
respectively, pre-trained on ImageNet with full supervision. (c) is
MirrorNet with our proposed SSL framework and without supervised ImageNet
pre-training. Our SSL scheme leverages the mirror reflection cue and avoids
feature redundancy in the pre-training stage. It outperforms those
pre-trained on ImageNet with full supervision (i.e., (b) and (c)).
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where the mirrors are.
Abstract. Existing mirror
detection methods require supervised ImageNet pre-training to obtain good
general-purpose image features. However, supervised ImageNet pre-training focuses
on category-level discrimination and may not be suitable for downstream tasks
like mirror detection, due to the overfitting upstream tasks (e.g.,
supervised image classification). We observe that mirror reflection is
crucial to how people perceive the presence of mirrors, and such mid-level features
can be better transferred from self-supervised pretrained models. Inspired by
this observation, in this paper we aim to improve mirror detection methods by
proposing a new self-supervised learning (SSL) pre-training framework for
modeling the representation of mirror reflection progressively in the
pre-training process. Our framework consists of three pre-training stages at
different levels: 1) an image-level pre-training stage to globally
incorporate mirror reflection features into the pre-trained model; 2) a
patch-level pre-training stage to spatially simulate and learn local mirror
reflection from image patches; and 3) a pixel-level pre-training stage to
pixel-wisely capture mirror reflection via reconstructing corrupted mirror
images based on the relationship between the inside and outside of mirrors. Extensive
experiments show that our SSL pre-training framework significantly
outperforms previous state-of-the-art CNN-based SSL pre-training frameworks
and even outperforms supervised ImageNet pre-training when transferred to the
mirror detection task.
|
|
Learning to Detect Mirrors from
Videos via Dual Correspondences [paper] [suppl] [model]
[dataset]
Jiaying Lin, Xin Tan, and Rynson Lau
Proc. IEEE CVPR, June 2023
|
|
|

Although state-of-the-art single-image mirror
detection method VCNet [36] performs well on a single image (e.g., the
first row) by using implicitly intra-frame correspondence, it may fail when
the intra-frame cue is weak or even absent in some video frames (e.g., the
second and third rows). The lack in exploiting inter-frame information
causes the current mirror detection methods to produce inaccurate and
inconsistent results when applied to VMD. In contrast, our method can
perform well in both situations by utilizing the proposed dual
correspondence module to exploit intra-frame (spatial) and inter-frame
(temporal) correspondences.
|
|
|
Input-Output: Given an input video, our network
outputs a sequence of binary masks indicating where the mirrors are in each
frame.
Abstract. Detecting mirrors from static
images has received significant research interest recently. However,
detecting mirrors over dynamic scenes is still under-explored due to the lack
of a high-quality dataset and an effective method for video mirror detection
(VMD). To the best of our knowledge, this is the first work to address the
VMD problem from a deep-learning-based perspective. Our observation is that
there are often correspondences between the contents inside (reflected) and
outside (real) of a mirror, but such correspondences may not always appear in
every frame, e.g., due to the change of camera pose. This inspires us to
propose a video mirror detection method, named VMD-Net, that can tolerate
spatially missing correspondences by considering the mirror correspondences
at both the intra-frame level as well as inter-frame level via a dual
correspondence module that looks over multiple frames spatially and temporally
for correlating correspondences. We further propose a first large-scale
dataset for VMD (named VMD-D), which contains 14,987 image frames from 269
videos with corresponding manually annotated masks. Experimental results show
that the proposed method outperforms SOTA methods from relevant fields. To
enable real-time VMD, our method efficiently utilizes the backbone features
by removing the redundant multi-level module design and gets rid of
postprocessing of the output maps commonly used in existing methods, making
it very efficient and practical for real-time video-based applications.
|
|
Mirror Detection with the Visual
Chirality Cue [paper] [code]
Xin Tan, Jiaying Lin, Ke Xu, Pan Chen,
Lizhuang Ma, and Rynson Lau
IEEE Trans. on
Pattern Analysis and Machine Intelligence, 45(3):3492-3504, Mar. 2023
|
|
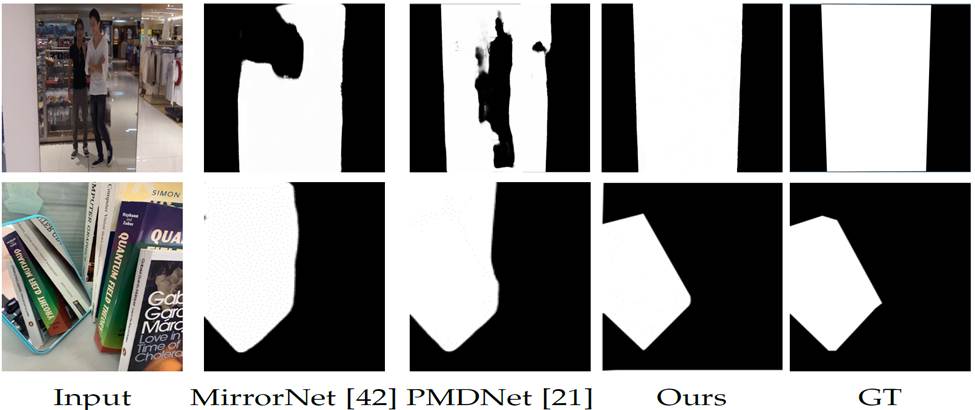
Existing single image based mirror detection
methods [42] [21], which are based on modeling contrasts/correspondences
between mirror and non-mirror regions, may fail when these relations are
not reliable. For example, MirrorNet [42] would fail if the contrasts
between mirror/non-mirror regions are weak (top row) or have multiple
degrees (bottom row). PMDNet [21] would fail if correspondences do not
exist (top row) or are incorrectly detected (bottom row). Our method (Ours)
leverages the visual chirality cue, which is an intrinsic property of
mirrors reflecting real-world scenes, to accurately differentiate mirror
and non-mirror regions.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where the mirrors are.
Abstract. Mirror detection is
challenging because the visual appearances of mirrors change depending on
those of their surroundings. As existing mirror detection methods are mainly
based on extracting contextual contrast and relational similarity between mirror
and non-mirror regions, they may fail to identify a mirror region if these
assumptions are violated. Inspired by a recent study of applying a CNN to
help distinguish whether an image is flipped or not based on the visual
chirality property, in this paper, we rethink this image-level visual
chirality property and reformulate it as a learnable pixel level cue for
mirror detection. Specifically, we first propose a novel
flipping-convolution-flipping (FCF) transformation to model visual chirality
as learnable commutative residual. We then propose a novel visual chirality
embedding (VCE) module to exploit this commutative residual in multi-scale
feature maps, to embed the visual chirality features into our mirror
detection model. Besides, we also propose a visual chirality-guided edge
detection (CED) module to integrate the visual chirality features with
contextual features for detection refinement. Extensive experiments show that
the proposed method outperforms state-of-the-art methods on three benchmark
datasets.
|
|
Large-Field Contextual Feature
Learning for Glass Detection [paper] [code]
Haiyang Mei, Xin Yang, Letian Yu, Qiang
Zhang, Xiaopeng Wei, and Rynson Lau
IEEE Trans. on
Pattern Analysis and Machine Intelligence, 45(3):3329-3346, March
2023
|
|
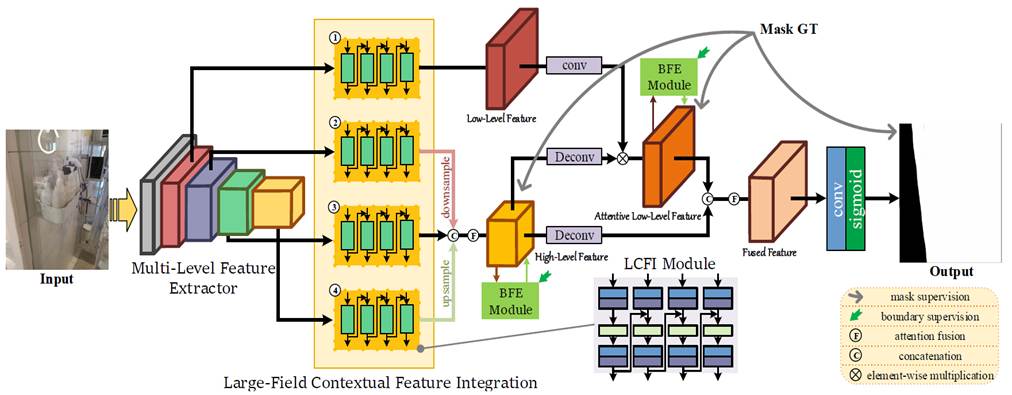
The pipeline of the proposed GDNet-B. First, we
use the pre-trained ResNeXt-101 [75] as a multi-level feature extractor
(MFE) to obtain features of different levels. Second, we embed four LCFI
modules to the last four layers of MFE, to learn large-field contextual
features at different levels. Third, the outputs of the last three LCFI
modules are concatenated and fused via an attention module [76] to generate
high-level large-field contextual features. An attention map is then
learned from these high-level large-field contextual features and used to guide
the low-level large-field contextual features, i.e., the output of the
first LCFI module, to focus more on glass regions. Fourth, we apply two BFE
modules on the highlevel/attentive low-level large-field contextual
features to further perceive and integrate boundary cues. Finally, we
combine high-level and attentive low-level large-field contextual features
by concatenation and attention [76] operations to produce the final glass
detection map.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where glass surfaces are.
Abstract. Glass is very common
in our daily life. Existing computer vision systems neglect it and thus may
have severe consequences, e.g., a robot may crash into a glass wall. However,
sensing the presence of glass is not straightforward. The key challenge is
that arbitrary objects/scenes can appear behind the glass. In this paper, we
propose an important problem of detecting glass surfaces from a single RGB
image. To address this problem, we construct the first large-scale glass
detection dataset (GDD) and propose a novel glass detection network, called
GDNet-B, which explores abundant contextual cues in a large field-of-view via
a novel large-field contextual feature integration (LCFI) module and
integrates both high-level and low-level boundary features with a boundary feature
enhancement (BFE) module. Extensive experiments demonstrate that our GDNet-B
achieves satisfying glass detection results on the images within and beyond
the GDD testing set. We further validate the effectiveness and generalization
capability of our proposed GDNet-B by applying it to other vision tasks,
including mirror segmentation and salient object detection. Finally, we show
the potential applications of glass detection and discuss possible future
research directions.
|
|
Symmetry-Aware Transformer-based
Mirror Detection [paper] [model]
Tianyu Huang, Bowen Dong, Jiaying Lin,
Xiaohui Liu, Rynson Lau, and Wangmeng Zuo
Proc. AAAI, Feb. 2023
|
|

Comparison of mirror detection among state-of-the-art
methods. MirrorNet (Yang et al. 2019) cannot handle scenes with vague
mirror boundaries. Although PMDNet (Lin, Wang, and Lau 2020) considers
similarity semantics, it can hardly detect the symmetry pair (1st row), and
can easily count part of the similar non-mirror regions into mirrors (2nd
row). SANet (Guan, Lin, and Lau 2022) only detects the mirror region above
the sink (1st row), and it has worse predictions when semantic associations
are lacking (2nd row). By modeling a loose symmetry relationship, SATNet
succeeds in both cases.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where the mirrors are.
Abstract. Mirror detection aims
to identify the mirror regions in the given input image. Existing works
mainly focus on integrating the semantic features and structural features to
mine specific relations between mirror and non-mirror regions, or introducing
mirror properties like depth or chirality to help analyze the existence of
mirrors. In this work, we observe that a real object typically forms a loose
symmetry relationship with its corresponding reflection in the mirror, which is
beneficial in distinguishing mirrors from real objects. Based on this
observation, we propose a dual-path Symmetry-Aware Transformer-based mirror
detection Network (SATNet), which includes two novel modules: Symmetry-Aware Attention
Module (SAAM) and Contrast and Fusion Decoder Module (CFDM). Specifically, we
first adopt a transformer backbone to model global information aggregation in
images, extracting multi-scale features in two paths. We then feed the high-level
dual-path features to SAAMs to capture the symmetry relations. Finally, we
fuse the dual-path features and refine our prediction maps progressively with
CFDMs to obtain the final mirror mask. Experimental results show that SATNet outperforms
both RGB and RGB-D mirror detection methods on all available mirror detection
datasets.
|
|
Efficient Mirror Detection via
Multi-level Heterogeneous Learning (Oral
Presentation) [paper] [model]
Ruozhen He, Jiaying Lin, and Rynson Lau
Proc. AAAI, Feb. 2023
|
|
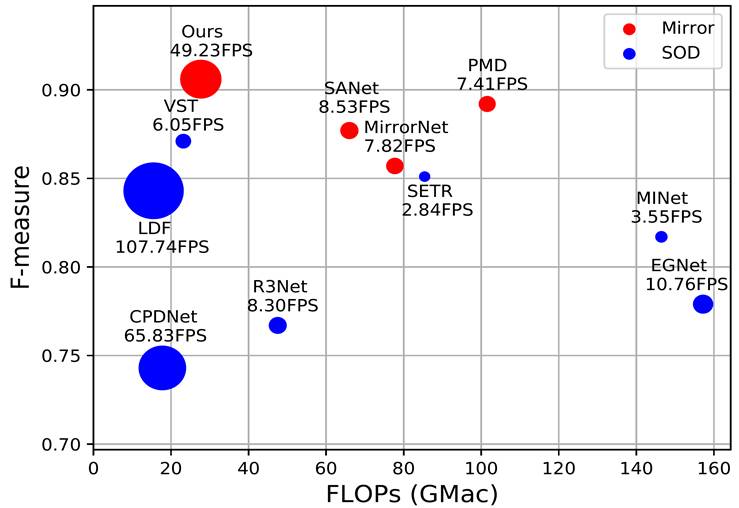
Comparison of our proposed method with mirror detection
and SOD models on F-measure, FLOPs, and FPS using the MSD dataset. Our
method achieves a new SOTA result with considerable efficiency.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where the mirrors are.
Abstract. We present HetNet (Multi-level
Heterogeneous Network), a highly efficient mirror detection network. Current
mirror detection methods focus more on performance than efficiency, limiting
the real-time applications (such as drones). Their lack of efficiency is
aroused by the common design of adopting homogeneous modules at different
levels, which ignores the difference between different levels of features. In
contrast, HetNet detects potential mirror regions initially through low-level
understandings (e.g., intensity contrasts) and then combines with high-level
understandings (contextual discontinuity for instance) to finalize the
predictions. To perform accurate yet efficient mirror detection, HetNet
follows an effective architecture that obtains specific information at
different stages to detect mirrors. We further propose a multi-orientation intensity-based
contrasted module (MIC) and a reflection semantic logical module (RSL),
equipped on HetNet, to predict potential mirror regions by low-level
understandings and analyze semantic logic in scenarios by high-level understandings,
respectively. Compared to the state-of-the-art method, HetNet runs 664%
faster and draws an average performance gain of 8.9% on MAE, 3.1% on IoU, and
2.0% on F-measure on two mirror detection benchmarks.
|
|
Exploiting Semantic Relations for
Glass Surface Detection (Spotlight Presentation) [paper] [code] [dataset]
Jiaying Lin*, Yuen Hei Yeung*,
and Rynson Lau (* joint first authors)
Proc. NeurIPS, Nov. 2022
|
|

Visual
comparisons of our method to state-of-the-art methods for glass surface
detection [8, 18] on some example images.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where glass surfaces are.
Abstract. Glass surfaces are omnipresent
in our daily lives and often go unnoticed by the majority of us. While humans
are generally able to infer their locations and thus avoid collisions, it can
be difficult for current object detection systems to handle them due to the
transparent nature of glass surfaces. Previous methods approached the problem
by extracting global context information to obtain priors such as boundary
and reflection. However, their performances cannot be guaranteed when these
critical features are not available. We observe that humans often reason through
the semantic context of the environment, which offers insights into the categories
of and proximity between entities that are expected to appear in the surrounding.
For example, the odds of co-occurrence of glass windows with walls and
curtains is generally higher than that with other objects such as cars and
trees, which have relatively less semantic relevance. Based on this
observation, we propose a model that integrates the contextual relationship
of the scene for glass surface detection with two novel modules: (1) Scene
Aware Activation (SAA) Module to adaptively filter critical channels with
respect to spatial and semantic features, and (2) Context Correlation
Attention (CCA) Module to progressively learn the contextual correlations
among objects both spatially and semantically. In addition, we propose a
large-scale glass surface detection dataset named GSD-S, which contains 4,519
real-world RGB glass surface images from diverse real-world scenes with
detailed annotations. Experimental results show that our model outperforms
contemporary works, especially with 48.8% improvement on MAE from our
proposed GSD-S dataset.
|
|
Learning Semantic Associations
for Mirror Detection [paper] [suppl] [code] [dataset]
Huankang Guan, Jiaying Lin, and Rynson
Lau
Proc. IEEE CVPR, June 2022
|
|

Existing mirror detection methods based on
learning contextual contrasts [47] or corresponding relations [24] falsely identify
some distractors (e.g., the doorway in the 1st row and the painting
in the 2nd row) as mirrors, and miss the mirror (3rd
row) when the mirror is captured at an oblique angle to the camera along with
some occluding lights. In contrast, our method considers the semantic
associations between mirrors and their surrounding objects (e.g., the
vanity table in the 1st row and the sink in the 2nd and 3rd
rows), yielding accurate results.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where the mirrors are.
Abstract. Mirrors generally lack a
consistent visual appearance, making mirror detection very challenging.
Although recent works that are based on exploiting contextual contrasts and
corresponding relations have achieved good results, heavily relying on
contextual contrasts and corresponding relations to discover mirrors tend to
fail in complex real-world scenes, where a lot of objects, e.g., doorways, may
have similar features as mirrors. We observe that humans tend to place
mirrors in relation to certain objects for specific functional purposes,
e.g., a mirror above the sink. Inspired by this observation, we propose a
model to exploit the semantic associations between the mirror and its
surrounding objects for a reliable mirror localization. Our model first
acquires class-specific knowledge of the surrounding objects via a semantic
side-path. It then uses two novel modules to exploit semantic associations:
1) an Associations Exploration (AE) Module to extract the associations of the
scene objects based on fully connected graph models, and 2) a Quadruple-Graph
(QG) Module to facilitate the diffusion and aggregation of semantic association
knowledge using graph convolutions. Extensive experiments show that our
method outperforms the existing methods and sets the new state-of-the-art on
both PMD dataset (f-measure: 0.844) and MSD dataset (f-measure: 0.889).
|
|
Rich Context Aggregation with
Reflection Prior for Glass Surface Detection [paper] [suppl] [video] [pretrained code] [dataset]
Jiaying Lin, Zebang He, and Rynson Lau
Proc. IEEE CVPR, June 2021
|
|

Two popular scenarios where existing methods [20,
30] fail. GDNet [20] is based on extracting/integrating abundant context
features for glass surface detection. As it does not consider any specific
glass properties, it tends to fail in scenes with insufficient contexts
(e.g., top row where the glass surface covers almost the whole image) or
with glass-lookalike regions (e.g., bottom row where the center region is
not covered by glass). TransLab [30] is based on a boundary-guided network
for transparent object detection. It also fails to detect glass surfaces
correctly. Our method, which considers reflections and boundaries, can
accurately detect the glass surfaces in these complex scenes.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where glass surfaces are.
Abstract. Glass surfaces appear
everywhere. Their existence can however pose a serious problem to computer
vision tasks. Recently, a method is proposed to detect glass surfaces by learning
multi-scale contextual information. However, as it is only based on a general
context integration operation and does not consider any specific glass
surface properties, it gets confused when the images contain objects that are
similar to glass surfaces and degenerates in challenging scenes with
insufficient contexts. We observe that humans often rely on identifying
reflections in order to sense the existence of glass and on locating the
boundary in order to determine the extent of the glass. Hence, we propose a
model for glass surface detection, which consists of two novel modules: (1) a
rich context aggregation module (RCAM) to extract multi-scale boundary
features from rich context features for locating glass surface boundaries of
different sizes and shapes, and (2) a reflection-based refinement module (RRM)
to detect reflection and then incorporate it so as to differentiate glass
regions from non-glass regions. In addition, we also propose a challenging
dataset consisting of 4,012 glass images with annotations for glass surface
detection. Our experiments demonstrate that the proposed model outperforms
state-of-the-art methods from relevant fields.
|
|
Progressive Mirror Detection [paper] [suppl] [code] [dataset]
Jiaying Lin, Guodong Wang, and Rynson
Lau
Proc. IEEE CVPR, June 2020
|
|

Visualization of our progressive approach to
recognizing mirrors from a single image. By finding correspondences between
objects inside and outside of the mirror and then explicitly locating the
miror edges, we can detect the mirror region more reliably.
|
|
|
Input-Output: Given an input image, our network
outputs a binary mask that indicates where the mirrors are.
Abstract. The mirror detection problem is
important as mirrors can affect the performances of many vision tasks. It is
a difficult problem since it requires an understanding of global scene
semantics. Recently, a method was proposed to detect mirrors by learning
multi-level contextual contrasts between inside and outside of mirrors, which
helps locate mirror edges implicitly. We observe that the content of a mirror
reflects the content of its surrounding, separated by the edge of the mirror.
Hence, we propose a model in this paper to progressively learn the content
similarity between the inside and outside of the mirror while explicitly
detecting the mirror edges. Our work has two main contributions. First, we
propose a new relational contextual contrasted local (RCCL) module to extract
and compare the mirror features with its corresponding context features, and
an edge detection and fusion (EDF) module to learn the features of mirror edges
in complex scenes via explicit supervision. Second, we construct a
challenging benchmark dataset of 6,461 mirror images. Unlike the existing MSD
dataset, which has limited diversity, our dataset covers a variety of scenes
and is much larger in scale. Experimental results show that our model
outperforms relevant state-of-the-art methods.
|
|
Don't Hit Me! Glass Detection
in Real-world Scenes
[paper] [suppl] [code]
[dataset]
Haiyang
Mei, Xin Yang, Yang Wang, Yuanyuan Liu, Shengfeng He, Qiang Zhang, Xiaopeng
Wei, and Rynson Lau
Proc. IEEE CVPR, June 2020
|
|
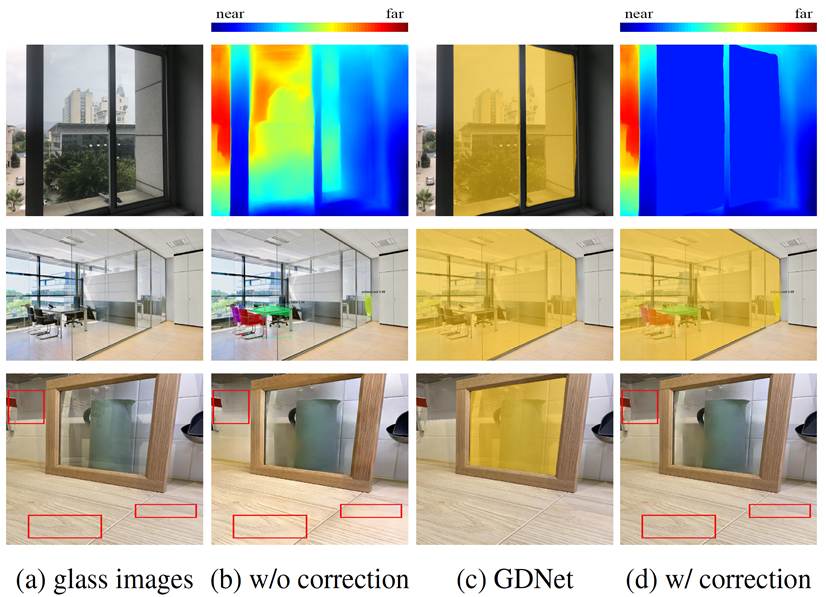
Problems with glass in existing vision tasks. In
depth prediction, existing method [16] wrongly predicts the depth of the scene
behind the glass, instead of the depth to the glass (1st row of (b)). For
instance segmentation, Mask RCNN [9] only segments the instances behind
the glass, not aware that they are actually behind the glass (2nd row of
(b)). Besides, if we directly apply an existing singe-image reflection
removal (SIRR) method [36] to an image that is only partially covered by
glass, the non-glass region can be corrupted (3rd row of (b)). GDNet can
detect the glass (c) and then correct these failure cases (d).
|
|
|
Input-Output: Given an input
image, our network outputs a binary mask that indicates where glass
surfaces are.
Abstract. Transparent glass
is very common in our daily life. Existing computer vision systems neglect
it and thus may have severe consequences, e.g., a robot may crash into a
glass wall. However, sensing the presence of glass is not straightforward. The
key challenge is that arbitrary objects/scenes can appear behind the glass,
and the content within the glass region is typically similar to those
behind it. In this paper, we propose an important problem of detecting
glass from a single RGB image. To address this problem, we construct a
large-scale glass detection dataset (GDD) and design a glass detection
network, called GDNet, which explores abundant contextual cues for robust
glass detection with a novel large-field contextual feature integration
(LCFI) module. Extensive experiments demonstrate that the proposed method
achieves more superior glass detection results on our GDD test set than
state-of-the-art methods fine-tuned for glass detection.
|
|
|
Where is My Mirror? [paper] [suppl] [code and
updated results] [dataset]
Xin
Yang*, Haiyang Mei*, Ke Xu, Xiaopeng Wei, Baocai Yin, and Rynson Lau (*
joint first authors)
Proc. IEEE ICCV, Oct. 2019
|
|

Problems with mirrors in existing vision tasks.
In depth prediction, NYU-v2 dataset [32] uses a Kinect to capture depth
as ground truth. It wrongly predicts the depths of the reflected
contents, instead of the mirror depths (b). In instance semantic segmentation,
Mask RCNN [12] wrongly detects objects inside the mirrors (c). With
MirrorNet, we first detect and mask out the mirrors (d). We then obtain
the correct depths (e), by interpolating the depths from surrounding
pixels of the mirrors, and segmentation maps (f).
|
|
|
Input-Output: Given an input
image, our network outputs a binary mask that indicates where the mirrors
are.
Abstract. Mirrors are
everywhere in our daily lives. Existing computer vision systems do not
consider mirrors, and hence may get confused by the reflected content
inside a mirror, resulting in a severe performance degradation. However, separating
the real content outside a mirror from the reflected content inside it is
non-trivial. The key challenge is that mirrors typically reflect contents
similar to their surroundings, making it very difficult to differentiate
the two. In this paper, we present a novel method to segment mirrors from
an input image. To the best of our knowledge, this is the first work to
address the mirror segmentation problem with a computational approach. We
make the following contributions. First, we construct a large-scale mirror
dataset that contains mirror images with corresponding manually annotated
masks. This dataset covers a variety of daily life scenes, and will be made
publicly available for future research. Second, we propose a novel network,
called MirrorNet, for mirror segmentation, by modeling both semantical and
low-level color/texture discontinuities between the contents inside and
outside of the mirrors. Third, we conduct extensive experiments to evaluate
the proposed method, and show that it outperforms the carefully chosen
baselines from the state-of-the-art detection and segmentation methods
|
|