|
Graphic
Design Layout
|
|
Graphics layout concerns about the arrangement
of graphic design elements to form a structure that can achieve some
objectives. While the layout may refer to a 2D page, a 2D image, a 2D/3D
object, or a 3D scene, the objectives of the layout may include visual
aesthetics and functionality. The arrangement of graphic design elements is
typically via the adjustment of their properties, such as location,
orientation, color, size and shape. In this project, we aim at developing automatic/interactive
tools for synthesizing novel layouts. In particular, we are interested in
learning the design rules through the data-driven approach, using machine
learning or deep learning techniques. We can then use the learned layout
features to synthesize novel layouts. Concurrent to this project, we are also
investigating how visual saliency may affect graphic design layout. (See also
our work on image saliency.)
|
|
Language-based Photo Color Adjustment for Graphic
Designs
[paper] [suppl] [video] [code]
[dataset]
Zhenwei
Wang, Nanuxan Zhan, Gerhard Hancke, and Rynson Lau
ACM Trans. on
Graphics
(presented at SIGGRAPH 2023), 42(4), 2023
|
|

|
Language-based photo recoloring of a graphic
design. Given a graphic design containing an inserted photo (a), our model
recolors the photo automatically according to the given language-based
instruction. To facilitate the expression of various user intentions, our
model supports multi-granularity instructions for describing the source
color(s) (selected from the design elements) and the region(s) to be
modified (selected from the photo). For example, the user may provide a
coarse-grained instruction ( background in (b)) to refer to multiple
source colors or a fine-grained instruction ( yellow shape in (c), i.e.,
using the yellow shape at the top left) to specify a source color. For
visualization, we highlight the source colors predicted by our model at the
bottom (colors inside the circles).
|
|
|
Abstract. Adjusting the photo
color to associate with some design elements is an essential way for a
graphic design to effectively deliver its message and make it aesthetically
pleasing. However, existing tools and previous works face a dilemma between
the ease of use and level of expressiveness. To this end, we introduce an
interactive language-based approach for photo recoloring, which provides an
intuitive system that can assist both experts and novices on graphic design.
Given a graphic design containing a photo that needs to be recolored, our
model can predict the source colors and the target regions, and then recolor
the target regions with the source colors based on the given language-based
instruction. The multi-granularity of the instruction allows diverse user
intentions. The proposed novel task faces several unique challenges,
including: 1) color accuracy for recoloring with exactly the same color from
the target design element as specified by the user; 2) multi-granularity
instructions for parsing instructions correctly to generate a specific result
or multiple plausible ones; and 3) locality for recoloring in semantically
meaningful local regions to preserve original image semantics. To address
these challenges, we propose a model called LangRecol with two main
components: the language-based source color prediction module and the
semantic-palette-based photo recoloring module. We also introduce an approach
for generating a synthetic graphic design dataset with instructions to enable
model training. We evaluate our model via extensive experiments and user
studies. We also discuss several practical applications, showing the
effectiveness and practicality of our approach.
|
|
Design Order Guided Visual Note Optimization [paper]
Xiaotian
Qiao, Ying Cao, and Rynson Lau
IEEE Trans. on
Visualization and Computer Graphics, 29(9):3922-3936, 2023
|
|

|
Layout optimization results. For each example,
given an input visual note (left), we predict its grid-based global design
order (upper middle) and element-wise design order (lower middle). Based on
the predicated design order, the layout of the visual note is automatically
optimized such that it is easier for readers to follow along (right).
|
|
|
Abstract. With the goal of
making contents easy to understand, memorize and share, a clear and
easy-to-follow layout is important for visual notes. Unfortunately, since
visual notes are often taken by the designers in real time while watching a
video or listening to a presentation, the contents are usually not carefully
structured, resulting in layouts that may be difficult for others to follow.
In this paper, we address this problem by proposing a novel approach to
automatically optimize the layouts of visual notes. Our approach predicts the
design order of a visual note and then warps the contents along the predicted
design order such that the visual note can be easier to follow and
understand. At the core of our approach is a learning-based framework to
reason about the element-wise design orders of visual notes. In particular,
we first propose a hierarchical LSTM-based architecture to predict a
grid-based design order of the visual note, based on the graphical and
textual information. We then derive the element-wise order from the
grid-based prediction. Such an idea allows our network to be
weakly-supervised, i.e., making it possible to predict dense grid-based
orders from visual notes with only coarse annotations. We evaluate the
effectiveness of our approach on visual notes with diverse content densities
and layouts. The results show that our network can predict plausible design
orders for various types of visual notes and our approach can effectively optimize
their layouts in order for them to be easier to follow.
|
|
Selective Region-based Photo Color Adjustment for
Graphic Designs
[paper] [suppl] [video]
[code] [dataset]
Nanxuan
Zhao, Quanlong Zheng, Jing Liao, Ying Cao, Hanspeter Pfister, and Rynson Lau
ACM Trans. on
Graphics
(presented at SIGGRAPH 2021), 40(2), 2021
|
|

|
Photo color adjustment results in the context of
graphic designs. When inserting a photo into a graphic design (see the
input designs on the left), our model can automatically predict modifiable
regions and recolor these regions with the target colors (see the color
bars at the bottom of the input designs) to form the output design (see our
designs on the right). We show results generated by our model with a single
target color in the first row and with multiple target colors in the second
row. We can see that our method can suggest appropriate regions for
recoloring to the target colors, such that the resulting images still look
natural with the original object semantics preserved and the resulting
designs look visually more harmonious. Our model is also able to provide multiple
suggestions for the user to choose from (see the right-most example in the
bottom row).
|
|
|
Abstract. When adding a photo onto a graphic
design, professional graphic designers often adjust its colors based on some
target colors obtained from the brand or product to make the entire design
more memorable to audiences and establish a consistent brand identity.
However, adjusting the colors of a photo in the context of a graphic design
is a difficult task, with two major challenges: (1) Locality: the color is
often adjusted locally to preserve the semantics and atmosphere of the
original image; (2) Naturalness: the modified region needs to be carefully
chosen and recolored to obtain a semantically valid and visually natural
result. To address these challenges, we propose a learning-based approach to
photo color adjustment for graphic designs, which maps an input photo along
with the target colors to a recolored result. Our method decomposes the color
adjustment process into two successive stages: modifiable region selection
and target color propagation. The first stage aims to solve the core,
challenging problem of which local image region(s) should be adjusted, which
requires not only a common sense of colors appearing in our visual world but
also understanding of subtle visual design heuristics. To this end, we
capitalize on both natural photos and graphic designs to train a region
selection network, which detects the most likely regions to be adjusted to
the target colors. The second stage trains a recoloring network to naturally
propagate the target colors in the detected regions. Through extensive
experiments and a user study, we demonstrate the effectiveness of our
selective region-based photo recoloring framework.
|
|
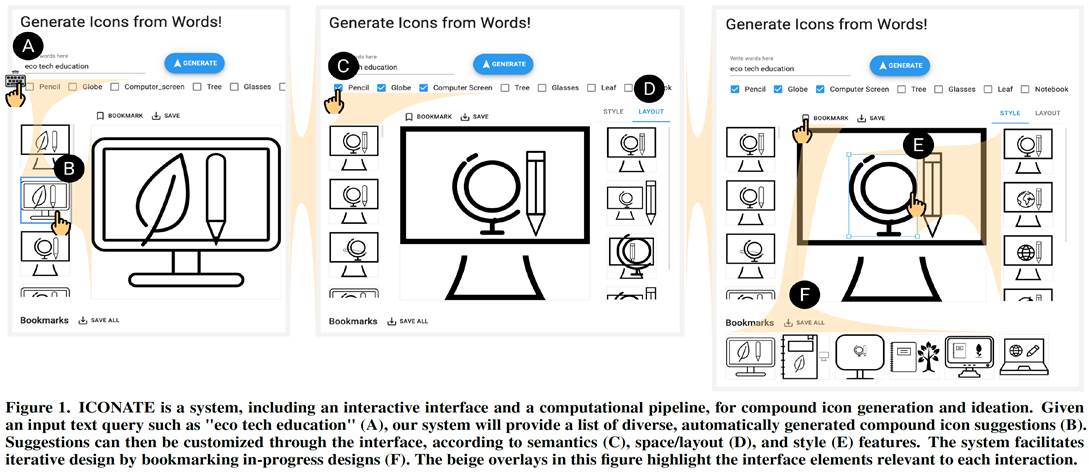
ICONATE: Automatic Compound Icon Generation and
Ideation
[paper] [suppl] [code] [IconVoc152]
Nanxuan
Zhao, Nam Wook Kim, Laura Mariah Herman, Hanspeter Pfister, Rynson Lau, Jose
Echevarria, and Zoya Bylinskii
Proc. ACM SIGCHI, April 2020
|
|
|
|
Abstract. Compound icons are prevalent on
signs, webpages, and infographics, effectively conveying complex and abstract
concepts, such as "no smoking" and "health insurance",
with simple graphical representations. However, designing such icons requires
experience and creativity, in order to efficiently navigate the semantics,
space, and style features of icons. In this paper, we aim to automate the
process of generating icons given compound concepts, to facilitate rapid
compound icon creation and ideation. Informed by ethnographic interviews with
professional icon designers, we have developed ICONATE, a novel system that
automatically generates compound icons based on textual queries and allows
users to explore and customize the generated icons. At the core of ICONATE is
a computational pipeline that automatically finds commonly used icons for
sub-concepts and arranges them according to inferred conventions. To enable
the pipeline, we collected a new dataset, Compicon1k, consisting of 1000
compound icons annotated with semantic labels (i.e., concepts). Through user
studies, we have demonstrated that our tool is able to automate or accelerate
the compound icon design process for both novices and professionals.
|
|
Content-aware Generative Modeling of Graphic Design
Layouts
[paper] [suppl] [code] [dataset]
Xinru
Zheng*, Xiaotian Qiao*, Ying Cao, and Rynson Lau (* joint first
authors)
ACM Trans. on
Graphics (Proc. ACM SIGGRAPH 2019), 38(4), July 2019
|
|
|
|
Abstract. Layout is fundamental to graphic
designs. For visual attractiveness and efficient communication of messages
and ideas, graphic design layouts often have great variation, driven by the
contents to be presented. In this paper, we study the problem of
content-aware graphic design layout generation. We propose a deep generative
model for graphic design layouts that is able to synthesize layout designs
based on the visual and textual semantics of user inputs. Unlike previous
approaches that are oblivious to the input contents and rely on heuristic
criteria, our model captures the effect of visual and textual contents on
layouts, and implicitly learns complex layout structure variations from data
without the use of any heuristic rules. To train our model, we build a
large-scale magazine layout dataset with fine-grained layout annotations and
keyword labeling. Experimental results show that our model can synthesize
high-quality layouts based on the visual semantics of input images and
keyword-based summary of input text. We also demonstrate that our model
internally learns powerful features that capture the subtle interaction
between contents and layouts, which are useful for layout-aware design
retrieval.
|
|
ButtonTips: Design Web Buttons with Suggestions (Oral) [paper]
Dawei
Liu, Ying Cao, Rynson Lau, and Antoni Chan
Proc. IEEE ICME, July 2019
|
|

Fig.
2. Overview of our method. Given a web design being edited without
buttons (a), the button presence prediction step proposes a set of
candidate regions (orange boxes) that roughly contains buttons, and the
button layout prediction step will then provide a button layout (blue
box) for each candidate region. After the user selects a button layout,
the color selection step will automatically select suitable color for it
(c). Best viewed in color.
|
|
|
|
Abstract. Buttons are fundamental in web
design. An effective button is important for higher click-through and
conversion rates. However, designing effective buttons can be challenging for
novices. This paper presents a novel interactive method to aid the button
design process by making design suggestions. Our method proceeds in three
steps: 1) button presence prediction, 2) button layout suggestion and 3)
button color selection. We investigate two distinct but complementary interfaces
for button design suggestion: 1) region selection interface, where the button
will appear in a user-specific region; 2) element selection interface, where
the button will be associated with a user-selected element. We compare our
method with an existing website building tool, and show that for novice
designers, both interfaces require significantly less manual efforts, and
produce significantly better button design, as evaluated by professional web
designers.
|
|
Tell Me Where I Am: Object-level
Scene Context Prediction (Oral) [paper] [suppl] [code]
Xiaotian
Qiao, Quanlong Zheng, Ying Cao, and Rynson Lau
Proc. IEEE CVPR, June 2019
|
|
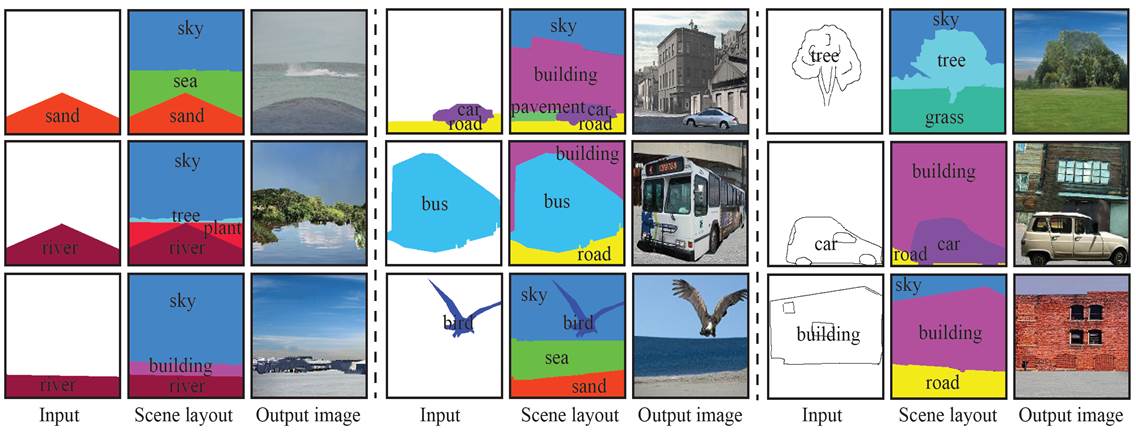
Given
a partial scene layout or a sketch as input, our method is able to
generate a complete scene layout and further synthesize a realistic full
scene image.
|
|
|
|
Abstract. Contextual
information has been shown to be effective in helping solve various image
understanding tasks. Previous works have focused on the extraction of
contextual information from an image and use it to infer the properties of
some object(s) in the image. In this paper, we consider an inverse problem
of how to hallucinate missing contextual information from the properties of
a few standalone objects. We refer to it as scene context prediction. This problem
is difficult as it requires an extensive knowledge of complex and diverse
relationships among different objects in natural scenes. We propose a
convolutional neural network, which takes as input the properties (i.e.,
category, shape, and position) of a few standalone objects to predict an
object-level scene layout that compactly encodes the semantics and
structure of the scene context where the given objects are. Our
quantitative experiments and user studies show that our model can generate
more plausible scene context than the baseline approach. We demonstrate
that our model allows for the synthesis of realistic scene images from just
partial scene layouts and internally learns useful features for scene
recognition.
|
|
Modeling Fonts in Context: Font
Prediction on Web Design [paper] [suppl] [CTXFont-dataset]
Nanxuan
Zhao, Ying Cao, and Rynson Lau
Computer Graphics
Forum (Proc. Pacific Graphics 2018), Oct. 2018
|
|
|
|
Abstract. Web designers often
carefully select fonts to fit the context of a web design to make the
design look aesthetically pleasing and effective in communication. However,
selecting proper fonts for a web design is a tedious and time-consuming
task, as each font has many properties, such as font face, color, and size,
resulting in a very large search space. In this paper, we aim to model
fonts in context, by studying a novel and challenging problem of predicting
fonts that match a given web design. To this end, we propose a novel,
multi-task deep neural network to jointly predict font face, color and size
for each text element on a web design, by considering multi-scale visual
features and semantic tags of the web design. To train our model, we have
collected a CTXFont dataset, which consists of 1k professional web designs,
with labeled font properties. Experiments show that our model outperforms
the baseline methods, achieving promising qualitative and quantitative
results on the font selection task. We also demonstrate the usefulness of
our method in a font selection task via a user study.
|
|
Task-driven Webpage Saliency [paper] [suppl]
Quanlong
Zheng, Jianbo Jiao, Ying Cao, and Rynson Lau
Proc. ECCV, Sept. 2018
|
|

Given an input webpage (a), our model can
predict a different saliency map under a different task, e.g.,
information browsing (b), form filling (c) and shopping (d).
|
|
|
Abstract. In this paper, we
present an end-to-end learning framework for predicting task-driven visual
saliency on webpages. Given a webpage, we propose a convolutional neural
network to predict where people look at it under different task conditions.
Inspired by the observation that given a specific task, human attention is
strongly correlated with certain semantic components on a webpage (e.g.,
images, buttons and input boxes), our network explicitly disentangles
saliency prediction into two independent sub-tasks: task-specific attention
shift prediction and task-free saliency prediction. The task-specific
branch estimates task-driven attention shift over a webpage from its
semantic components, while the task-free branch infers visual saliency
induced by visual features of the webpage. The outputs of the two branches
are combined to produce the final prediction. Such a task decomposition
framework allows us to efficiently learn our model from a small-scale
task-driven saliency dataset with sparse labels (captured under a single
task condition). Experimental results show that our method outperforms the
baselines and prior works, achieving state-of-the-art performance on a
newly collected benchmark dataset for task-driven webpage saliency
detection.
|
|
|
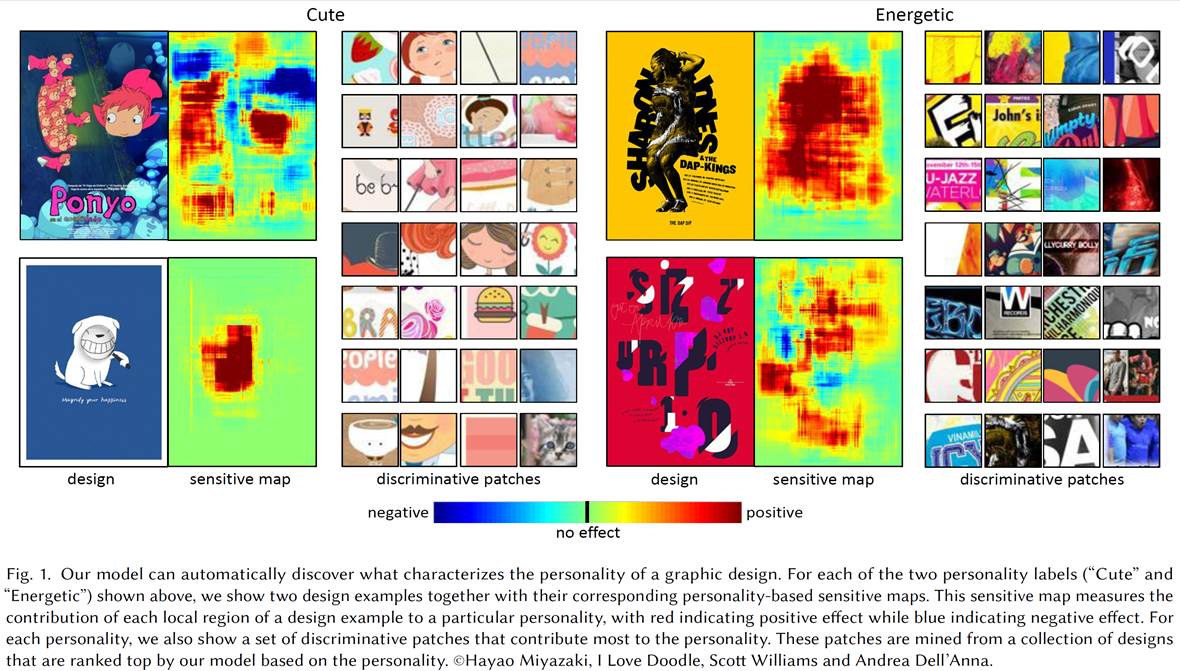
What Characterizes
Personalities of Graphic Designs? [paper] [suppl] [video] [code] [dataset]
Nanxuan
Zhao, Ying Cao, and Rynson Lau
ACM Trans. on
Graphics (Proc. ACM SIGGRAPH 2018), 37(4), Aug. 2018
|
|
|
|
Abstract: Graphic designers
often manipulate the overall look and feel of their designs to convey
certain personalities (e.g., cute, mysterious and romantic) to impress
potential audiences and achieve business goals. However, understanding the
factors that determine the personality of a design is challenging, as a
graphic design is often a result of thousands of decisions on numerous
factors, such as font, color, image, and layout. In this paper, we aim to
answer the question of what characterizes the personality of a graphic
design. To this end, we propose a deep learning framework for exploring the
effects of various design factors on the perceived personalities of graphic
designs. Our framework learns a convolutional neural network (called
personality scoring network) to estimate the personality scores of graphic
designs by ranking the crawled web data. Our personality scoring network
automatically learns a visual representation that captures the semantics
necessary to predict graphic design personality. With our personality
scoring network, we systematically and quantitatively investigate how
various design factors (e.g., color, font, and layout) affect design
personality across different scales (from pixels, regions to elements). We
also demonstrate a number of practical application scenarios of our
network, including element-level design suggestion and example-based
personality transfer.
|
|
|
Directing User Attention via
Visual Flow on Web Designs [paper] [suppl] [video] [models] [dataset]
Xufang
Pang*, Ying Cao*, Rynson Lau, and Antoni Chan (* joint first
authors)
ACM Trans. on
Graphics (Proc. ACM SIGGRAPH Asia 2016), 35(6), Article 240,
Dec. 2016
US Patent 11,275,596
B2 (Publication
Date: Mar 15, 2022)
|
|
|
|
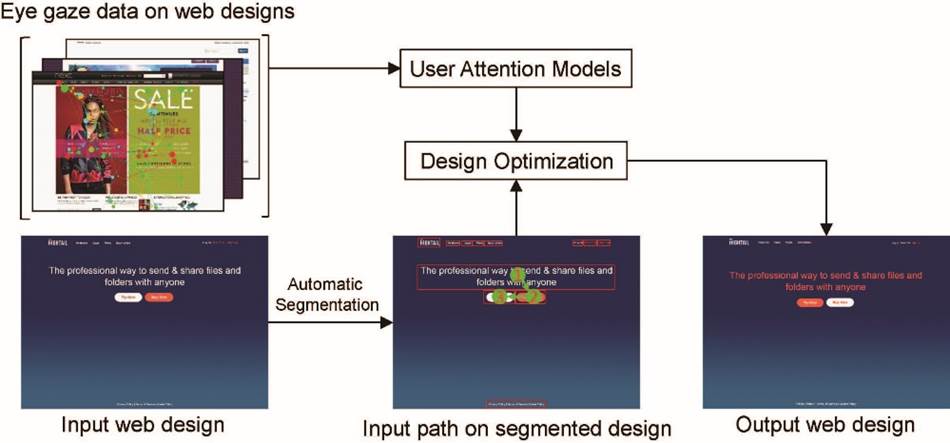
Abstract: We present a novel
approach that allows web designers to easily direct user attention via
visual flow on web designs. By collecting and analyzing users' eye gaze
data on real-world webpages under the task-driven condition, we build two
user attention models that characterize user attention patterns between a
pair of page components. These models enable a novel web design interaction
for designers to easily create a visual flow to guide users' eyes (i.e.,
direct user attention along a given path) through a web design with minimal
effort. In particular, given an existing web design as well as a
designer-specified path over a subset of page components, our approach
automatically optimizes the web design so that the resulting design can
direct users' attention to move along the input path. We have tested our
approach on various web designs of different categories. Results show that
our approach can effectively guide user attention through the web design
according to the designer's high-level specification.
|
|
|
Look Over Here:
Attention-Directing Composition of Manga Elements [paper] [suppl] [video]
Ying
Cao, Rynson Lau, and Antoni Chan
ACM Trans. on
Graphics (Proc. ACM SIGGRAPH 2014), 33(4), Article 94,
Aug. 2014
|
|
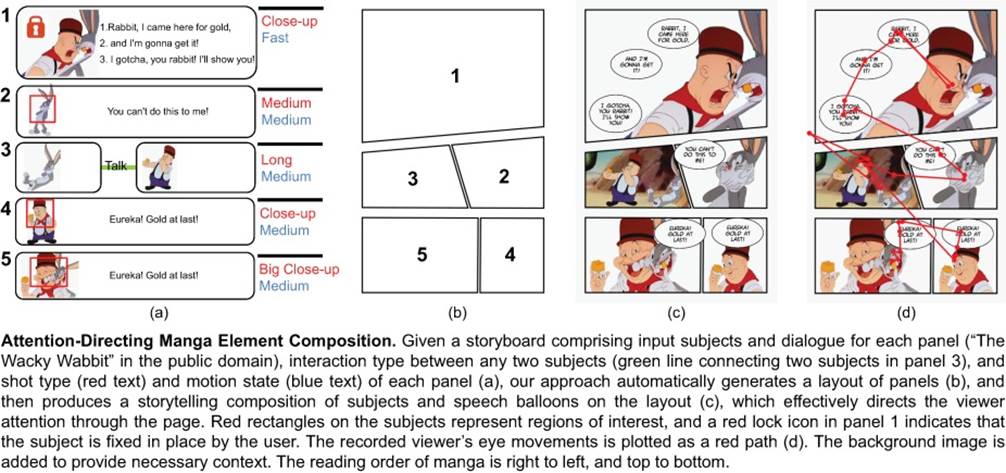
|
|
Abstract:
Picture subjects and text balloons are basic elements in comics, working
together to propel the story forward. Japanese comics artists often
leverage a carefully designed composition of subjects and balloons
(generally referred to as panel elements) to provide a continuous and fluid
reading experience. However, such a composition is hard to produce for
people without the required experience and knowledge. In this paper, we
propose an approach for novices to synthesize a composition of panel
elements that can effectively guide the reader's attention to convey the
story. Our primary contribution is a probabilistic graphical model that
describes the relationships among the artist's guiding path, the panel
elements, and the viewer attention, which can be effectively learned from a
small set of existing manga pages. We show that the proposed approach can
measurably improve the readability, visual appeal, and communication of the
story of the resulting pages, as compared to an existing method. We also
demonstrate that the proposed approach enables novice users to create
higher-quality compositions with less time, compared with commercially
available programs.
|
|
|
Structured Mechanical Collage [paper] [video] [more results]
Zhe
Huang, Jiang Wang, Hongbo Fu, and Rynson Lau
IEEE Trans. on
Visualization and Computer Graphics, 20(7):1076-1082, July
2014
|
|
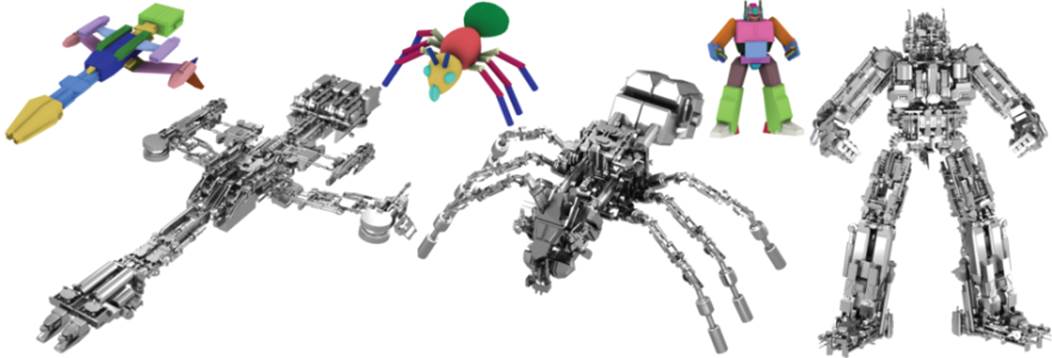
|
|
Abstract: We present a method
to build 3D structured mechanical collages consisting of numerous elements
from the database given artist-designed proxy models. The construction is
guided by some graphic design principles, namely unity, variety and
contrast. Our results are visually more pleasing than previous works as
confirmed by a user study.
|
|
|
Automatic Stylistic Manga
Layout [paper] [video] [more results]
Ying
Cao, Antoni Chan, and Rynson Lau
ACM Trans. on
Graphics (Proc. ACM SIGGRAPH Asia 2012), 31(6), Article 141,
Nov. 2012
|
|

|
|
Abstract:
Manga layout is a core component in manga production, characterized by its
unique styles. However, stylistic manga layouts are difficult for novices
to produce as it requires hands-on experience and domain knowledge. In this
paper, we propose an approach to automatically generate a stylistic manga
layout from a set of input artworks with user-specified semantics, thus
allowing less-experienced users to create high-quality manga layouts with
minimal efforts. We first introduce three parametric style models that
encode the unique stylistic aspects of manga layouts, including layout
structure, panel importance, and panel shape. Next, we propose a two-stage
approach to generate a manga layout: 1) an initial layout is created that
best fits the input artworks and layout structure model, according to a
generative probabilistic framework; 2) the layout and artwork geometries
are jointly refined using an efficient optimization procedure, resulting in
a professional-looking manga layout. Through a user study, we demonstrate
that our approach enables novice users to easily and quickly produce
higher-quality layouts that exhibit realistic manga styles, when compared
to a commercially-available manual layout tool.
|
|