|
Learning to Detect
Instance-level Salient Objects using Complementary Image Labels [paper]
Xin
Tian*, Ke Xu*, Xin Yang, Baocai Yin, and Rynson Lau (* joint
first authors)
International
Journal of Computer Vision (IJCV), accepted
|
|
|
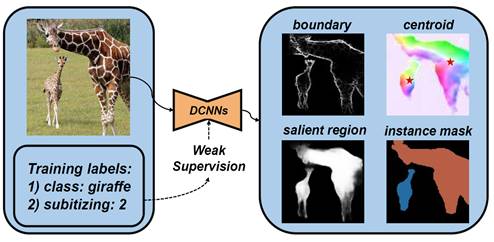
The key idea of this work is to
leverage complementary image-level labels (class and subitizing) to train
a salient instance detection model in a weakly-supervised manner, via
synergically learning to predict salient objects, detecting object boundaries
and locating instance centroids.
|
|
|
|
Input-Output:
Given an
input image, our network outputs an instance saliency map that indicates
the individual salient instances. It requires only class labels and
subitizing information as supervision in training.
Abstract. Existing salient instance
detection (SID) methods typically learn from pixel-level annotated
datasets. In this paper, we present the first weakly-supervised approach to
the SID problem. Although weak supervision has been considered in general
saliency detection, it is mainly based on using class labels for object
localization. However, it is non-trivial to use only class labels to learn
instance-aware saliency information, as salient instances with high
semantic affinities may not be easily separated by the labels. As the
subitizing information provides an instant judgement on the number of
salient items, it is naturally related to detecting salient instances and
may help separate instances of the same class while grouping different
parts of the same instance. Inspired by this observation, we propose to use
class and subitizing labels as weak supervision for the SID problem. We
propose a novel weakly-supervised network with three branches: a Saliency
Detection Branch leveraging class consistency information to locate
candidate objects; a Boundary Detection Branch exploiting class discrepancy
information to delineate object boundaries; and a Centroid Detection Branch
using subitizing information to detect salient instance centroids. This
complementary information is then fused to produce a salient instance map.
To facilitate the learning process, we further propose a progressive
training scheme to reduce label noise and the corresponding noise learned
by the model, via reciprocating the model with progressive salient instance
prediction and model refreshing. Our extensive evaluations show that the
proposed method plays favorably against carefully designed baseline methods
adapted from related tasks.
|
|
|
Scene Context-Aware Salient
Object Detection
[paper] [suppl] [video] [code] [dataset]
Avishek
Siris, Jianbo Jiao, Gary Tam, Xianghua Xie, and Rynson Lau
Proc. IEEE ICCV, Oct. 2021
|
|
|
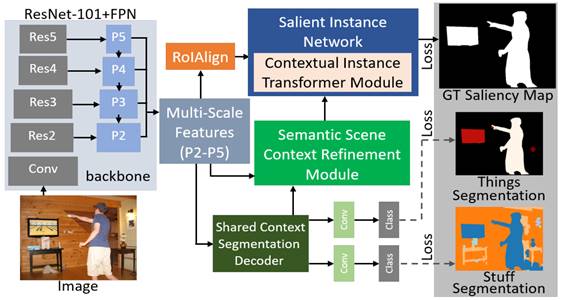
An overview of the proposed
network. The model extracts semantic features from the Shared Context
Segmentation Decoder. The decoder is trained to reconstruct features for
generating Things and Stuff categories. The Semantic Scene Context Refinement
(SSCR) module then utilizes the semantic features and multi-scale
features to build the augmented scene context features, correlating the
semantics of an image. The Contextual Instance Transformer (CIT) module
inside the Salient Instance Network learns relationships between objects and
scene context, to enhance saliency reasoning.
|
|
|
|
Input-Output:
Given an
input image, our proposed network outputs an object saliency map through
explicitly exploiting semantic scene contexts.
Abstract. Salient object detection
identifies objects in an image that grab visual attention. Although
contextual features are considered in recent literature, they often fail in
real-world complex scenarios. We observe that this is mainly due to two
issues: First, most existing datasets consist of simple foregrounds and
backgrounds that hardly represent real-life scenarios. Second, current
methods only learn contextual features of salient objects, which are
insufficient to model high-level semantics for saliency reasoning in
complex scenes. To address these problems, we first construct a new
large-scale dataset with complex scenes in this paper. We then propose a
context-aware learning approach to explicitly exploit the semantic scene contexts.
Specifically, two modules are proposed to achieve the goal: 1) a Semantic
Scene Context Refinement module to enhance contextual features learned from
salient objects with scene context, and 2) a Contextual Instance Transformer
to learn contextual relations between objects and scene context. To our
knowledge, such high-level semantic contextual information of image scenes
is underexplored for saliency detection in the literature. Extensive experiments
demonstrate that the proposed approach outperforms state-of-the-art
techniques in complex scenarios for saliency detection, and transfers well
to other existing datasets.
|
|
|
Weakly-Supervised Salient
Object Detection with Saliency Bounding Boxes [paper]
Yuxuan
Liu, Pengjie Wang, Ying Cao, Zijian Liang, and Rynson Lau
IEEE Trans. on
Image Processing,
30:4423-4435, 2021
|
|
|

(a)
Images with saliency bounding boxes (SBBs) that are marked in red. (b)
Saliency maps from an unsupervised method [2]. (c) Saliency maps from a
model using image-level category labels as supervision [2]. (d) Saliency
maps by our method using saliency bounding boxes as supervision. (e) Ground truth saliency maps.
|
|
|
Input-Output:
Given an
input image, our proposed model outputs a map of the salient objects. It
requires only bounding box supervision in training.
Abstract. In this paper, we propose a
novel form of weak supervision for salient object detection (SOD) based on
saliency bounding boxes, which are minimum rectangular boxes enclosing the
salient objects. Based on this idea, we propose a novel weakly-supervised
SOD method, by predicting pixel-level pseudo ground truth saliency maps
from just saliency bounding boxes. Our method first takes advantage of the
unsupervised SOD methods to generate initial saliency maps and addresses
the over/under prediction problems, to obtain the initial pseudo ground
truth saliency maps.We then iteratively refine the initial pseudo ground
truth by learning a multi-task map refinement network with saliency
bounding boxes. Finally, the final pseudo saliency maps are used to
supervise the training of a salient object detector. Experimental results
show that our method outperforms state-of-the-art weakly-supervised
methods.
|
|
|
Weakly-Supervised Saliency
Detection via Salient Object Subitizing [paper]
Xiaoyang
Zhang*, Xin Tan*, Jie Zhou, Lizhuang Ma, and Rynson Lau (* joint
first authors)
IEEE Trans. on Circuits and
Systems for Video Technology,
31(11):4370-4380, 2021
|
|
|
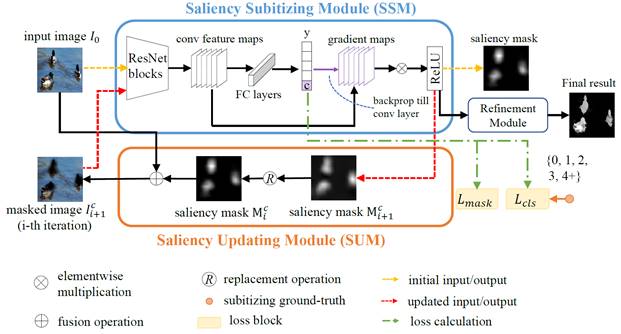
The pipeline of the proposed
network, with the Saliency Subitizing Module (SSM), the Saliency Updating
Module (SUM) and the refinement process. While SSM learns to generate the
initial saliency masks using the subitizing information, without the need
to use any unsupervised methods or random seeds, SUM helps iteratively
refine the generated saliency masks.
|
|
|
|
Input-Output:
Given an
input image, our proposed model outputs a map of the salient objects. It
requires only subitizing information as supervision in training.
Abstract. Salient object detection
aims at detecting the most visually distinct objects and producing the corresponding
masks. As the cost of pixel-level annotations is high, image tags are usually
used as weak supervisions. However, an image tag can only be used to
annotate one class of objects. In this paper, we introduce saliency
subitizing as the weak supervision since it is class-agnostic. This allows
the supervision to be aligned with the property of saliency detection,
where the salient objects of an image could be from more than one class. To
this end, we propose a model with two modules, Saliency Subitizing Module
(SSM) and Saliency Updating Module (SUM). While SSM learns to generate the
initial saliency masks using the subitizing information, without the need
for any unsupervised methods or some random seeds, SUM helps iteratively
refine the generated saliency masks. We conduct extensive experiments on five
benchmark datasets. The experimental results show that our method
outperforms other weakly-supervised methods and even performs comparable to
some fully-supervised methods.
|
|
|
Tactile Sketch Saliency [paper] [suppl] [video] [data and
code]
Jianbo
Jiao, Ying Cao, Manfred Lau, and Rynson Lau
Proc. ACM
Multimedia,
Oct. 2020
|
|

Given an input sketch shown on the
left of each pair of diagrams, we propose a novel problem of predicting the
tactile saliency map shown on the right to indicate where people would
likely grasp (e.g., for cup), press (e.g., for game controller) or touch
(e.g., for statue) the object depicted by the sketch.
|
|
|
Input-Output:
Given an
input sketch, our network outputs a tactile saliency map that indicates where
people tend to interact with the object depicted by the sketch.
Abstract. In this paper, we aim to
understand the functionality of 2D sketches by predicting how humans would
interact with the objects depicted by sketches in real life. Given a 2D
sketch, we learn to predict a tactile saliency map for it, which represents
where humans would grasp, press, or touch the object depicted by the
sketch. We hypothesize that understanding 3D structure and category of the
sketched object would help such tactile saliency reasoning. We thus propose
to jointly predict the tactile saliency, depth map and semantic category of
a sketch in an end-to-end learning-based framework. To train our model, we
propose to synthesize training data by leveraging a collection of 3D shapes
with 3D tactile saliency information. Experiments show that our model can
predict accurate and plausible tactile saliency maps for both synthetic and
real sketches. In addition, we also demonstrate that our predicted tactile
saliency is beneficial to sketch recognition and sketch-based 3D shape
retrieval, and enables us to establish part-based functional
correspondences among sketches.
|
|
Weakly-supervised Salient
Instance Detection (Oral - best student paper
runner up) [paper] [suppl]
Xin
Tian, Ke Xu, Xin Yang, Baocai Yin, and Rynson Lau
Proc. BMVC, Sept. 2020
|
|
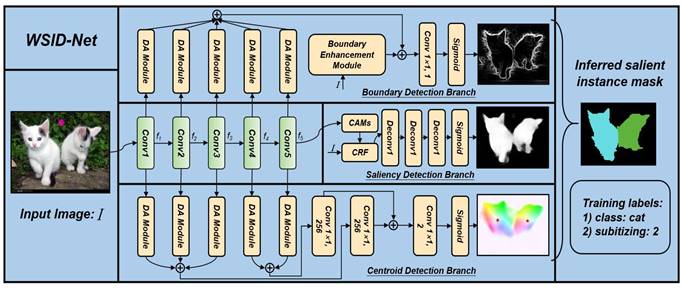
Pipeline overview. Our SID model
is trained only using image-level class and subitizing labels. It has
three synergic branches: (1) a Boundary Detection Branch for detecting object
boundaries using class discrepancy information; (2) a Saliency Detection
Branch for detecting objects using class consistency information; (3) a
Centroid Detection Branch for detecting salient instance centroids using
subitizing information. A random walk method is further applied to fuse
these information to obtain final salient instance mask.
|
|
|
Input-Output:
Given an
input image, our network outputs an instance saliency map that indicates
the individual salient instances.
Abstract. Existing salient instance
detection (SID) methods typically learn from pixel-level annotated
datasets. In this paper, we present the first weakly-supervised approach to
the SID problem. Although weak supervision has been considered in general
saliency detection, it is mainly based on using class labels for object
localization. However, it is non-trivial to use only class labels to learn
instance-aware saliency information, as salient instances with high
semantic affinities may not be easily separated by the labels. We note that
subitizing information provides an instant judgement on the number of salient
items, which naturally relates to detecting salient instances and may help
separate instances of the same class while grouping different parts of the
same instance. Inspired by this insight, we propose to use class and
subitizing labels as weak supervision for the SID problem. We propose a
novel weakly-supervised network with three branches: a Saliency Detection
Branch leveraging class consistency information to locate candidate objects;
a Boundary Detection Branch exploiting class discrepancy information to
delineate object boundaries; and a Centroid Detection Branch using subitizing
information to detect salient instance centroids. This complementary
information is further fused to produce salient instance maps. We conduct
extensive experiments to demonstrate that the proposed method plays
favorably against carefully designed baseline methods adapted from related
tasks.
|
|
Inferring Attention Shift
Ranks of Objects for Image Saliency [paper] [suppl] [code and
dataset]
Avishek
Siris, Jianbo Jiao, Gary K.L. Tam, Xianghua Xie, and Rynson Lau
Proc. IEEE CVPR, June 2020
|
|

Comparison of the proposed method
with state-of-the-art methods: RSDNet [1], S4Net [12], BASNet [45], CPD-R
[60] and SCRN [61]. Each example in the top row shows the input image,
ground-truth saliency map and ground-truth ranks, while for the following
rows: (i) saliency prediction map, (ii) saliency prediction map with
predicted rank of ground-truth object segments colourised on top, and (iii)
corresponding map that contains only the predicted rank of ground-truth
objects. The result in (iii) is leveraged to obtain the predicted saliency
ranks for quantitative evaluation.
|
|
|
Input-Output:
Given an
input image, our network outputs a saliency map that indicates the
attention shift ranks of the salient objects.
Abstract. Psychology studies and
behavioural observation show that humans shift their attention from one
location to another when viewing an image of a complex scene. This is due
to the limited capacity of the human visual system in simultaneously
processing multiple visual inputs. The sequential shifting of attention on
objects in a non-task oriented viewing can be seen as a form of saliency
ranking. Although there are methods proposed for predicting saliency rank,
they are not able to model this human attention shift well, as they are
primarily based on ranking saliency values from binary prediction.
Following psychological studies, in this paper, we propose to predict the
saliency rank by inferring human attention shift. Due to the lack of such
data, we first construct a large-scale salient object ranking dataset. The
saliency rank of objects is defined by the order that an observer attends
to these objects based on attention shift. The final saliency rank is an
average across the saliency ranks of multiple observers. We then propose a
learning-based CNN to leverage both bottom-up and top-down attention mechanisms
to predict the saliency rank. Experimental results show that the proposed
network achieves state-of-the-art performances on salient object rank
prediction.
|
|
|
|
|
|
|
|
|
|
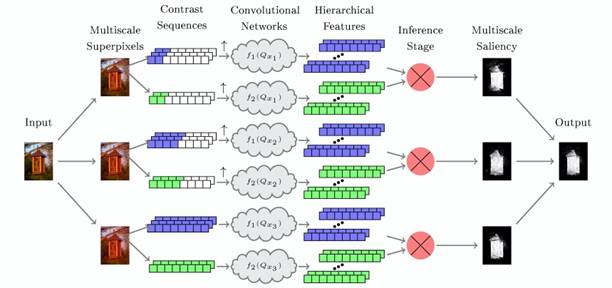
SuperCNN: A
Superpixelwise Convolution Neural Network for Salient Object Detection [paper]
Shengfeng
He, Rynson Lau, Wenxi Liu, Zhe Huang, and Qingxiong Yang
International
Journal of Computer Vision,
115(3):330-344, Dec. 2015
|
|
|
|
Input-Output: Given
an input image, our network detects the salient objects in it.
Abstract: Existing computational models
for salient object detection primarily rely on hand-crafted features, which
are only able to capture low-level contrast information. In this paper, we
learn the hierarchical contrast features by formulating salient object detection
as a binary labeling problem using deep learning techniques. A novel
superpixelwise convolutional neural network approach, called SuperCNN, is
proposed to learn the internal representations of saliency in an effi-
cient manner. In contrast to the classical convolutional networks, SuperCNN
has four main properties. First, the proposed method is able to learn the
hierarchical contrast features, as it is fed by two meaningful superpixel
sequences, which is much more effective for detecting salient regions than
feeding raw image pixels. Second, as SuperCNN recovers the contextual
information among superpixels, it enables large context to be involved in
the analysis efficiently. Third, benefiting from the superpixelwise
mechanism, the required number of predictions for a densely labeled map is
hugely reduced. Fourth, saliency can be detected independent of region size
by utilizing a multiscale network structure. Experiments show that SuperCNN
can robustly detect salient objects and outperforms the state-of-the-art
methods on three benchmark datasets.
|
|
|
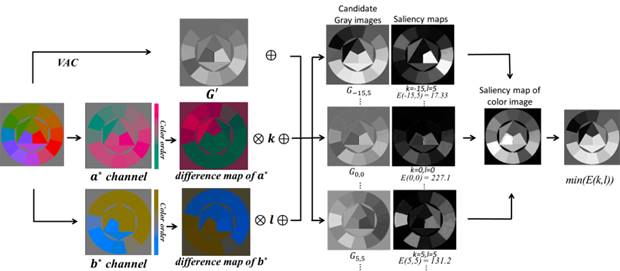
Saliency-Guided
Color-to-Gray Conversion using Region-based Optimization [paper] [suppl] [code] [demo] [CSDD Dataset] [Results on
CSDD]
[Result on
Cadik]
Hao
Du, Shengfeng He, Bin Sheng, Lizhaung Ma, and Rynson Lau
IEEE Trans. on
Image Processing,
24(1):434-443, Jan. 2015
|
|
|
|
Input-Output: Given
an input color image, our method converts it into an output grayscale
image.
Abstract: Image decolorization is a
fundamental problem for many real world applications, including monochrome
printing and photograph rendering. In this paper, we propose a new
color-to-gray conversion method that is based on a region-based saliency
model. First, we construct a parametric color-to-gray mapping function
based on global color information as well as local contrast. Second, we
propose a region-based saliency model that computes visual contrast among
pixel regions. Third, we minimize the salience difference between the
original color image and the output grayscale image in order to preserve
contrast discrimination. To evaluate the performance of the proposed method
in preserving contrast in complex scenarios, we have constructed a new
decolorization dataset with 22 images, each of which
contains abundant colors and patterns. Extensive experimental evaluations
on the existing and the new datasets show that the proposed method
outperforms the state-of-the-art methods quantitatively and qualitatively.
|
|
Saliency
Detection with Flash and No-flash Image Pairs [paper] [suppl] [dataset]
Shengfeng
He and Rynson Lau
Proc. ECCV, pp. 110-124, Sept. 2014.
|
|

|
|
Input-Output:
Given a pair
of flash/no-flash images, our method outputs the corresponding salient map.
Abstract: In this paper, we propose a
new saliency detection method using a pair of flash and no-flash images.
Our approach is inspired by two observations. First, only the foreground
objects are significantly brightened by the flash as they are relatively
nearer to the camera than the background. Second, the brightness variations
introduced by the flash provide hints to surface orientation changes.
Accordingly, the first observation is explored to form the background prior
to eliminate background distraction. The second observation provides a new
orientation cue to compute surface orientation contrast. These photometric
cues from the two observations are independent of visual attributes like
color, and they provide new and robust distinctiveness to support salient object
detection. The second observation further leads to the introduction of new
spatial priors to constrain the regions rendered salient to be compact both
in the image plane and in 3D space. We have constructed a new
flash/no-flash image dataset. Experiments on this dataset show that the
proposed method successfully identifies salient objects from various
challenging scenes that the state-of-the-art methods usually fail.
|
|