|
Tracking and
Animation
|
|
In this project, we initially wanted
to develop an algorithm for synthesizing realistic crowd motion behaviors,
driven by real crowd motion trajectories/behaviors captured from videos. We tried
to address two problems. First, we would like to develop tracking algorithms
to track real crowd motions and classify their behaviors. Second, we would
like to find out how to make use of the tracked crowd trajectories/behaviors
for synthesizing interactive crowd motions.
As we were
learning to track crowd motions, we became very interested in the object
tracking problem. Our recent works mainly focus on develop new techniques to
track a single object in videos.
|
|
Deformable Object Tracking with
Gated Fusion [paper] [code]
Wenxi
Liu, Yibing Song, Dengsheng Chen, Yuanlong Yu, Tao Yan, Shengfeng He,
Gerhard Hancke, and Rynson Lau
IEEE Trans. on
Image Processing
(to appear).
|
|
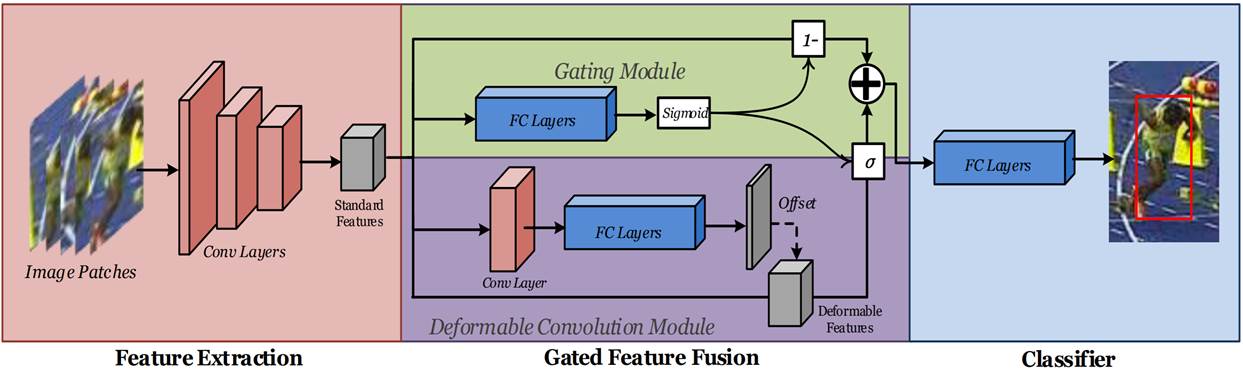
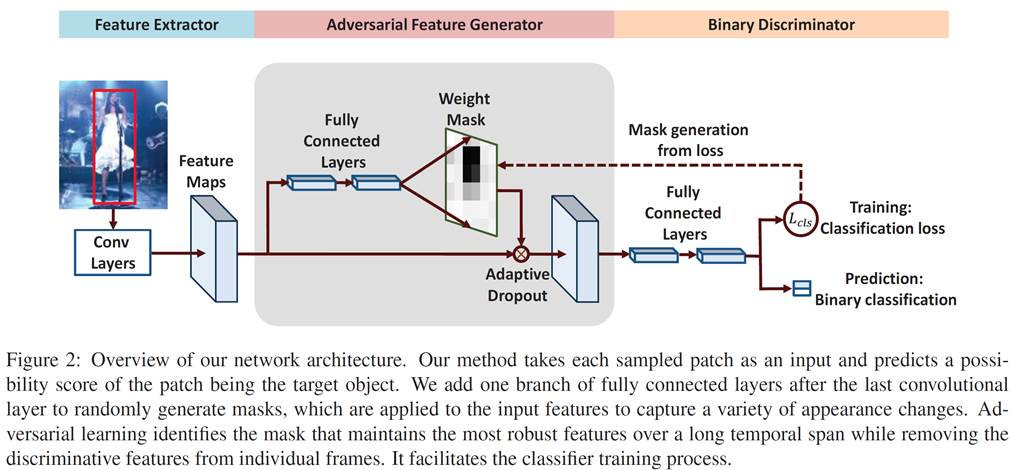
Our proposed framework is
composed of three stages: (1) feature extraction consisting of pretrained
convolutional layers, (2) gated feature fusion, and (3) classifier
consisting of fully connected layers. Our proposed method focuses on the
gated feature fusion, which includes a deformable convolution module, and
a gating module that controls the fusion of the deformable features and
the standard features.
|
|
|
Abstract. The tracking-by-detection
framework receives growing attentions through the integration with the
Convolutional Neural Networks (CNNs). Existing tracking-by-detection based
methods, however, fail to track objects with severe appearance variations.
This is because the traditional convolutional operation is performed on
fixed grids, and thus may not be able to find the correct response while
the object is changing pose or under varying environmental conditions. In
this paper, we propose a deformable convolution layer to enrich the target
appearance representations in the tracking-by-detection framework. We aim
to capture the target appearance variations via deformable convolution,
which adaptively enhances its original features. In addition, we also
propose a gated fusion scheme to control how the variations captured by the
deformable convolution affect the original appearance. The enriched feature
representation through deformable convolution facilitates the
discrimination of the CNN classifier on the target object and background.
Extensive experiments on the standard benchmarks show that the proposed
tracker performs favorably against state-of-the-art methods
|
|
VITAL: Visual Tracking via
Adversarial Learning
[paper] [video] [code]
Yibing
Song, Chao Ma, Xiaohe Wu, Lijun Gong, Linchao Bao, Wangmeng Zuo, Chunhua
Shen, Rynson Lau, Ming-Hsuan Yang
Proc. IEEE CVPR, pp. 8990-8999, June 2018.
|
|
|
|
Abstract. The tracking-by-detection
framework consists of two stages, i.e., drawing samples around the target
object in the first stage and classifying each sample as the target object or
as background in the second stage. The performance of existing trackers
using deep classification networks is limited by two aspects. First, the
positive samples in each frame are highly spatially overlapped, and they
fail to capture rich appearance variations. Second, there exists extreme
class imbalance between positive and negative samples. This paper presents
the VITAL algorithm to address these two problems via adversarial learning.
To augment positive samples, we use a generative network to randomly generate
masks, which are applied to adaptively dropout input features to capture a
variety of appearance changes. With the use of adversarial learning, our
network identifies the mask that maintains the most robust features of the target
objects over a long temporal span. In addition, to handle the issue of
class imbalance, we propose a high-order cost sensitive loss to decrease
the effect of easy negative samples to facilitate training the
classification network. Extensive experiments on benchmark datasets
demonstrate that the proposed tracker performs favorably against
state-of-the-art approaches.
|
|
CREST:
Convolutional Residual Learning for Visual Tracking [paper] [video] [code]
Yibing
Song, Chao Ma, Lijun Gong, Jiawei Zhang, Rynson Lau, and Ming-Hsuan Yang
Proc. IEEE ICCV,
pp. 2574-2583, Oct. 2017.
|
|
|
|
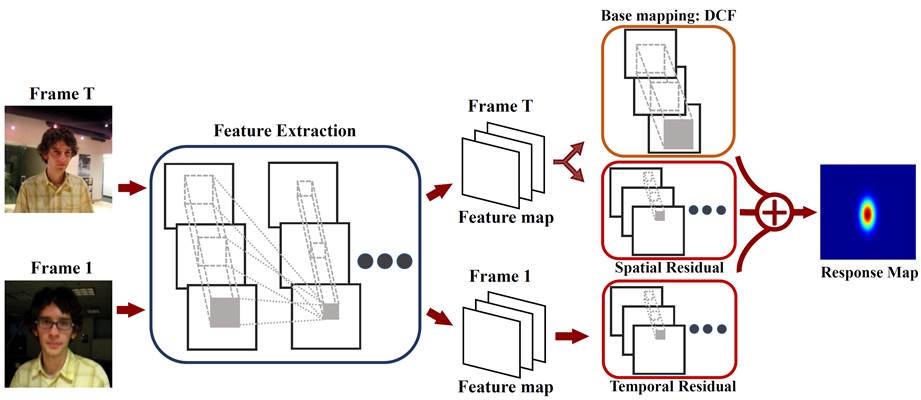
Abstract.
Discriminative
correlation filters (DCFs) have been shown to perform superiorly in visual
tracking. They only need a small set of training samples from the initial
frame to generate an appearance model. However, existing DCFs learn the
filters separately from feature extraction, and update these filters using
a moving average operation with an empirical weight. These DCF trackers
hardly benefit from the end-to-end training. In this paper, we propose the
CREST algorithm to reformulate DCFs as a one-layer convolutional neural
network. Our method integrates feature extraction, response map generation
as well as model update into the neural networks for an end-to-end
training. To reduce model degradation during online update, we apply
residual learning to take appearance changes into account. Extensive
experiments on the benchmark datasets demonstrate that our CREST tracker
performs favorably against state-of-the-art trackers.
|
|
Robust Object Tracking via
Locality Sensitive Histograms
[paper] [suppl]
[C code (color
LSH)]
Shengfeng
He, Rynson Lau, Qingxiong Yang, Jiang Wang, and Ming-Hsuan Yang
IEEE Trans. on
Circuits and Systems for Video Technology, 27(5):1006-1017, May 2017.
|
|
 
|
|
Abstract. This paper presents a novel
locality sensitive histogram (LSH) algorithm for visual tracking. Unlike
the conventional image histogram that counts the frequency of occurrence of
each intensity value by adding ones to the corresponding bin, a locality
sensitive histogram is computed at each pixel location and a floating-point
value is added to the corresponding bin for each occurrence of an intensity
value. The floating-point value reduces exponentially with respect to the
distance to the pixel location where the histogram is computed. An
efficient algorithm is proposed that enables the locality sensitive
histograms to be computed in time linear in the image size and the number
of bins. In addition, this efficient algorithm can be extended to exploit
color images. A robust tracking framework based on the locality sensitive
histograms is proposed, which consists of two main components: a new
feature for tracking that is robust to illumination change and a novel
multi-region tracking algorithm that runs in real-time even with hundreds
of regions. Extensive experiments demonstrate that the proposed tracking
framework outperforms the state-of-the-art methods in challenging
scenarios, especially when the illumination changes dramatically.
Evaluation using the latest benchmark shows that our algorithm is the top
performer.
|
|
|
Robust Individual and Holistic
Features for Crowd Scene Classification [paper]
Wenxi
Liu, Rynson Lau, and Dinesh Manocha
Pattern
Recognition,
58:110-120, Oct. 2016
|
|
|
|
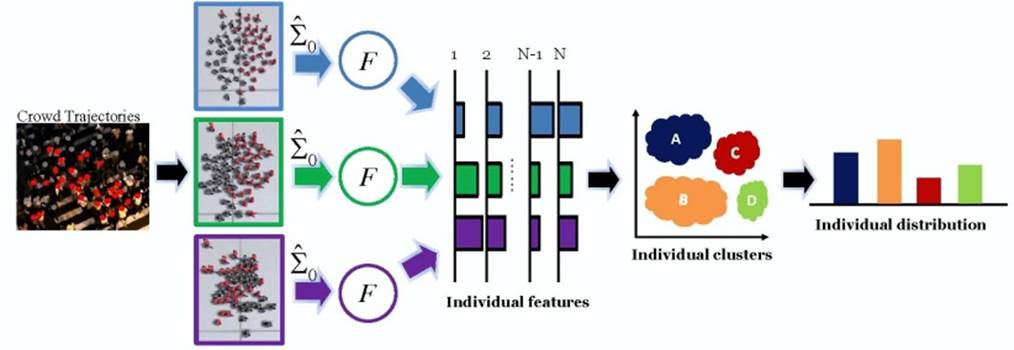
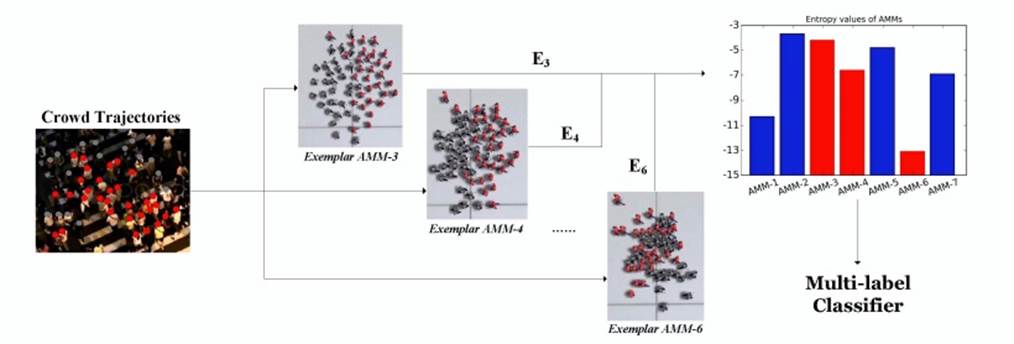
Abstract: In this paper, we present an
approach that utilizes multiple exemplar agent-based motion models (AMMs)
to extract motion features (representing crowd behaviors) from the captured
crowd trajectories. In the exemplar-based framework, we propose an iterative
optimization algorithm to measure the correlation between any exemplar AMM
and the trajectory data. It is based on the Extended Kalman Smoother and
KL-divergence. In addition, based on the proposed correlation measure, we
introduce the novel individual feature, in combination with the holistic
feature, to describe crowd motions. Our results show that the proposed
features perform well in classifying real-world crowd scenes.
|
|
|
Exemplar-AMMs: Recognizing
Crowd Movements from Pedestrian Trajectories [paper] [videos]
Wenxi
Liu, Rynson Lau, Xiaogang Wang, and Dinesh Manocha
IEEE Trans. on Multimedia, 18(12):2398-2406, Dec.
2016.
|
|
|
|
Abstract: In this paper, we present a
novel method to recognize the types of crowd movement from crowd
trajectories using agent-based motion models (AMMs). Our idea is to apply a
number of AMMs, referred to as exemplar-AMMs, to describe the crowd
movement. Specifically, we propose an optimization framework that filters
out the unknown noise in the crowd trajectories and measures their
similarity to the exemplar-AMMs to produce a crowd motion feature. We then
address our real-world crowd movement recognition problem as a multi-label
classification problem. Our experiments show that the proposed feature
outperforms the state-of-the-art methods in recognizing both simulated and
real-world crowd movements from their trajectories. Finally, we have
created a synthetic dataset, SynCrowd, which contains 2D crowd trajectories
in various scenarios, generated by various crowd simulators. This dataset
can serve as a training set or benchmark for crowd analysis work.
|
|
|
Leveraging Long-Term Predictions
and Online-Learning in Agent-based Multiple Person Tracking [paper]
Wenxi
Liu, Antoni Chan, Rynson Lau, and Dinesh Manocha
IEEE Trans. on
Circuits and Systems for Video Technologies, 25(3):399-410, Mar.
2015.
|
|
|
|
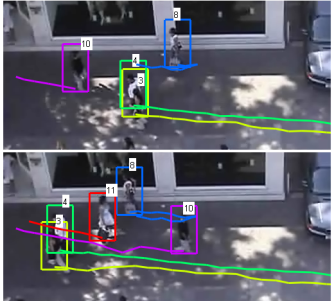
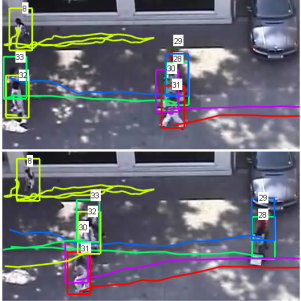
Abstract: We present a
multiple-person tracking algorithm, based on combining particle filters and
RVO, an agent-based crowd model that infers collision-free velocities so as
to predict pedestrian's motion. In addition to position and velocity, our
tracking algorithm can estimate the internal goals (desired destination or
desired velocity) of the tracked pedestrian in an online manner, thus
removing the need to specify this information beforehand. Furthermore, we
leverage the longer-term predictions of RVO by deriving a higher-order
particle filter, which aggregates multiple predictions from different prior
time steps. This yields a tracker that can recover from short-term
occlusions and spurious noise in the appearance model. Experimental results
show that our tracking algorithm is suitable for predicting pedestrians'
behaviors online without needing scene priors or hand-annotated goal
information, and improves tracking in real-world crowded scenes under low
frame rates.
|
|
|
BRVO: Predicting Pedestrian
Trajectories using Velocity-Space Reasoning [paper]
Sujeong
Kim, Stephen Guy, Wenxi Liu, David Wilkie, Rynson Lau, Ming Lin, and Dinesh
Manocha
International
Journal of Robotics Research, 34(2):201-217,
Feb. 2015.
|
|
|
|
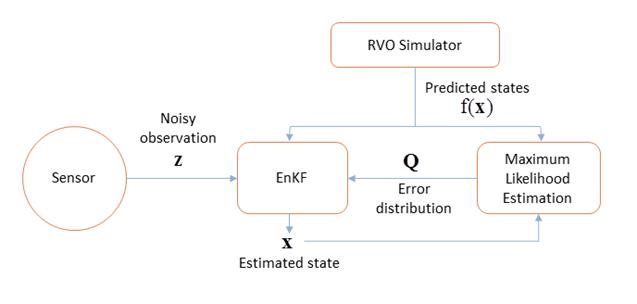
Abstract: We introduce a novel, online
method to predict pedestrian trajectories using agent-based velocity-space
reasoning for improved human-robot interaction and collision-free
navigation. Our formulation uses velocity obstacles to model the trajectory
of each moving pedestrian in a robot's environment and improves the motion
model by adaptively learning relevant parameters based on sensor data. The
resulting motion model for each agent is computed using statistical
inferencing techniques, including a combination of Ensemble Kalman filters
and a maximum-likelihood estimation algorithm. This allows a robot to learn
individual motion parameters for every agent in the scene at interactive
rates. We highlight the performance of our motion prediction method in
real-world crowded scenarios, compare its performance with prior
techniques, and demonstrate the improved accuracy of the predicted
trajectories. We also adapt our approach for collision-free robot
navigation among pedestrians based on noisy data and highlight the results
in our simulator.
|
|
|
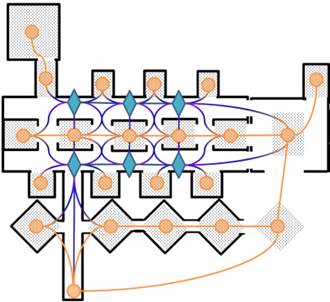
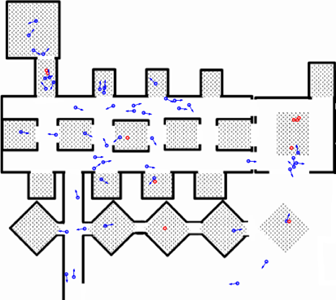
Data-driven Sequential Goal
Selection Model for Multi-agent Simulation [paper]
Wenxi
Liu, Zhe Huang, Rynson Lau, and Dinesh Manocha
Proc. ACM VRST, pp. 107-116, Nov. 2014.
|
|
|
|
Abstract: With recent advances
in distributed virtual worlds, online users have access to larger and more
immersive virtual environments. Sometimes the number of users in virtual
worlds is not large enough to make the virtual world realistic. In our
paper, we present a crowd simulation algorithm that allows a large number
of virtual agents to navigate around the virtual world autonomously by
sequentially selecting the goals. Our approach is based on our sequential
goal selection model (SGS) which can learn goal-selection patterns from
synthetic sequences. We demonstrate our algorithm's simulation results in
complex scenarios containing more than 20 goals.
|
|
Visual Tracking via Locality Sensitive
Histograms [paper] [suppl]
[videos]
Shengfeng He, Qingxiong Yang, Rynson Lau, Jiang Wang, and
Ming-Hsuan Yang
Proc. IEEE CVPR, pp. 2427-2434, June 2013.
|
|

|
|
Abstract: This paper presents a
novel locality sensitive histogram algorithm for visual tracking. Unlike
the conventional image histogram that counts the frequency of occurrences
of each intensity value by adding ones to the corresponding bin, a locality
sensitive histogram is computed at each pixel location and a floating-point
value is added to the corresponding bin for each occurrence of an intensity
value. The floating-point value declines exponentially with respect to the
distance to the pixel location where the histogram is computed; thus every
pixel is considered but those that are far away can be neglected due to the
very small weights assigned. An efficient algorithm is proposed that
enables the locality sensitive histograms to be computed in time linear in
the image size and the number of bins. A robust tracking framework based on
the locality sensitive histograms is proposed, which consists of two main
components: a new feature for tracking that is robust to illumination
changes and a novel multi-region tracking algorithm that runs in realtime
even with hundreds of regions. Extensive experiments demonstrate that the
proposed tracking framework outperforms the state-of-the-art methods in
challenging scenarios, especially when the illumination changes dramatically.
|
|
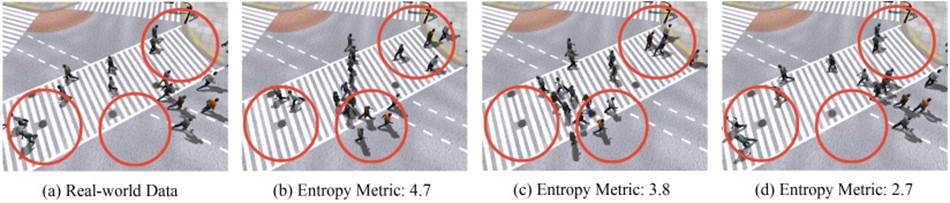
A Statistical Similarity Measure for
Aggregate Crowd Dynamics [paper] [video]
Stephen Guy,
Jur van den Berg, Wenxi Liu, Rynson Lau, Ming Lin, and Dinesh Manocha
ACM Trans. on
Graphics (SIGGRAPH Asia 2012),
31(6), Article 190, Nov. 2012.
|
|
|
|
Abstract: We present an
information-theoretic method to measure the similarity between a given set
of observed, real-world data and visual simulation technique for aggregate
crowd motions of a complex system consisting of many individual agents.
This metric uses a two-step process to quantify a simulator's ability to
reproduce the collective behaviors of the whole system, as observed in the
recorded real world data. First, Bayesian inference is used to estimate the
simulation states which best correspond to the observed data, then a
maximum likelihood estimator is used to approximate the prediction errors.
This process is iterated using the EM-algorithm to produce a robust,
statistical estimate of the magnitude of the prediction error as measured
by its entropy (smaller is better). This metric serves as a
simulator-to-data similarity measurement. We evaluated the metric in terms
of robustness to sensor noise, consistency across different datasets and
simulation methods, and correlation to perceptual metrics.
|
|
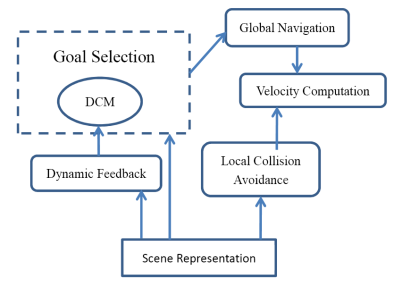
Crowd Simulation using Discrete Choice Model [paper]
Wenxi Liu, Rynson
Lau, and Dinesh Manocha
Proc. IEEE VR, pp. 3-6, Mar. 2012.
|
|
|
|
Abstract: We present a new
algorithm to simulate a variety of crowd behaviors using the Discrete
Choice Model (DCM). DCM has been widely studied in econometrics to examine
and predict customers' or households' choices. Our DCM formulation can
simulate virtual agents' goal selection and we highlight our algorithm by
simulating heterogeneous crowd behaviors: evacuation, shopping, and rioting
scenarios.
|
|