|
Saliency and
Object Detection
|
|
The human visual system can quickly
identify regions in a scene that attract our attention (saliency detection)
or contain objects (object detection). Such detection is typically driven by
low-level features. For saliency detection, it is generally referred to as
bottom-up saliency. On the other hand, if we are given a task to search for a
specific type of objects, the search is then based on high-level features
(sometimes together with low-level features). This is typically referred to
as top-down saliency.
In this project, we are developing
techniques to automatically detect objects or salient objects from input
images. We are looking at the detection problem using based on bottom-up as
well as top-down approaches.
|
|
Inferring Attention Shift Ranks
of Objects for Image Saliency
[paper] [suppl]
[code and dataset]
Avishek
Siris, Jianbo Jiao, Gary K.L. Tam, Xianghua Xie, and Rynson Lau
Proc. IEEE CVPR, June 2020
|
|

Comparison of the proposed method
with state-of-the-art methods: RSDNet [1], S4Net [12], BASNet [45], CPD-R
[60] and SCRN [61]. Each example in the top row shows the input image,
ground-truth saliency map and ground-truth ranks, while for the following
rows: (i) saliency prediction map, (ii) saliency prediction map with
predicted rank of ground-truth object segments colourised on top, and (iii)
corresponding map that contains only the predicted rank of ground-truth
objects. The result in (iii) is leveraged to obtain the predicted saliency
ranks for quantitative evaluation.
|
|
|
Input-Output:
Given an input
image, our network outputs a saliency map that indicates the attention
shift ranks of the salient objects.
Abstract. Psychology studies and
behavioural observation show that humans shift their attention from one
location to another when viewing an image of a complex scene. This is due
to the limited capacity of the human visual system in simultaneously
processing multiple visual inputs. The sequential shifting of attention on
objects in a non-task oriented viewing can be seen as a form of saliency
ranking. Although there are methods proposed for predicting saliency rank,
they are not able to model this human attention shift well, as they are
primarily based on ranking saliency values from binary prediction.
Following psychological studies, in this paper, we propose to predict the
saliency rank by inferring human attention shift. Due to the lack of such
data, we first construct a large-scale salient object ranking dataset. The
saliency rank of objects is defined by the order that an observer attends
to these objects based on attention shift. The final saliency rank is an
average across the saliency ranks of multiple observers. We then propose a
learning-based CNN to leverage both bottom-up and top-down attention mechanisms
to predict the saliency rank. Experimental results show that the proposed
network achieves state-of-the-art performances on salient object rank
prediction.
|
|
|
Where is My Mirror? [paper] [suppl]
[code and
updated results]
[dataset]
Xin
Yang*, Haiyang Mei*, Ke Xu, Xiaopeng Wei, Baocai Yin, and Rynson Lau (* joint first
authors)
Proc. IEEE ICCV, Oct. 2019
|
|

Problems with mirrors in existing
vision tasks. In depth prediction, NYU-v2 dataset [32] uses a Kinect to
capture depth as ground truth. It wrongly predicts the depths of the
reflected contents, instead of the mirror depths (b). In instance semantic
segmentation, Mask RCNN [12] wrongly detects objects inside the mirrors
(c). With MirrorNet, we first detect and mask out the mirrors (d). We
then obtain the correct depths (e), by interpolating the depths from
surrounding pixels of the mirrors, and segmentation maps (f).
|
|
|
Input-Output:
Given an input
image, our network outputs a binary mask that indicate where mirrors are.
Abstract. Mirrors are everywhere in our
daily lives. Existing computer vision systems do not consider mirrors, and
hence may get confused by the reflected content inside a mirror, resulting
in a severe performance degradation. However, separating the real content
outside a mirror from the reflected content inside it is non-trivial. The
key challenge is that mirrors typically reflect contents similar to their
surroundings, making it very difficult to differentiate the two. In this
paper, we present a novel method to segment mirrors from an input image. To
the best of our knowledge, this is the first work to address the mirror
segmentation problem with a computational approach. We make the following
contributions. First, we construct a large-scale mirror dataset that
contains mirror images with corresponding manually annotated masks. This
dataset covers a variety of daily life scenes, and will be made publicly
available for future research. Second, we propose a novel network, called
MirrorNet, for mirror segmentation, by modeling both semantical and
low-level color/texture discontinuities between the contents inside and
outside of the mirrors. Third, we conduct extensive experiments to evaluate
the proposed method, and show that it outperforms the carefully chosen
baselines from the state-of-the-art detection and segmentation methods
|
|
|
Task-driven Webpage Saliency [paper] [suppl]
Quanlong
Zheng, Jianbo Jiao, Ying Cao, and Rynson Lau
Proc. ECCV, Sept. 2018
|
|

Given an input webpage (a),
our model can predict a different saliency map under a different task,
e.g., information browsing (b), form filling (c) and shopping (d).
|
|
|
Input-Output:
Given an input
webpage and a specific task (e.g., information browsing, form filling and
shopping), our network detects the saliency of the webpage that is specific
to the given task.
Abstract. In this paper, we present an
end-to-end learning framework for predicting task-driven visual saliency on
webpages. Given a webpage, we propose a convolutional neural network to
predict where people look at it under different task conditions. Inspired
by the observation that given a specific task, human attention is strongly
correlated with certain semantic components on a webpage (e.g., images,
buttons and input boxes), our network explicitly disentangles saliency
prediction into two independent sub-tasks: task-specific attention shift
prediction and task-free saliency prediction. The task-specific branch
estimates task-driven attention shift over a webpage from its semantic
components, while the task-free branch infers visual saliency induced by
visual features of the webpage. The outputs of the two branches are
combined to produce the final prediction. Such a task decomposition
framework allows us to efficiently learn our model from a small-scale
task-driven saliency dataset with sparse labels (captured under a single
task condition). Experimental results show that our method outperforms the
baselines and prior works, achieving state-of-the-art performance on a
newly collected benchmark dataset for task-driven webpage saliency
detection.
|
|
|
Delving into
Salient Object Subitizing and Detection [paper]
Shengfeng
He, Jianbo Jiao, Xiaodan Zhang, Guoqiang Han, and Rynson Lau
Proc. IEEE ICCV, pp. 1059-1067, Oct. 2017
|
|

|
|
Input-Output: Given an input image, our
network detects the number of salient objects in it and outputs a salient
map containing the corresponding number of salient objects.
Abstract: Subitizing (i.e., instant
judgement on the number) and detection of salient objects are human inborn
abilities. These two tasks influence each other in the human visual system.
In this paper, we delve into the complementarity of these two tasks. We
propose a multi-task deep neural network with weight prediction for salient
object detection, where the parameters of an adaptive weight layer are
dynamically determined by an auxiliary subitizing network. The numerical
representation of salient objects is therefore embedded into the spatial
representation. The proposed joint network can be trained end-to-end using
backpropagation. Experiments show the proposed multi-task network
outperforms existing multi-task architectures, and the auxiliary subitizing
network provides strong guidance to salient object detection by reducing
false positives and producing coherent saliency maps. Moreover, the
proposed method is an unconstrained method able to handle images
with/without salient objects. Finally, we show state-of-the-art performance
on different salient object datasets.
|
|
|
Exemplar-Driven
Top-Down Saliency Detection via Deep Association [paper]
Shengfeng
He and Rynson Lau
Proc. IEEE CVPR, pp. 5723-5732, June 2016
|
|
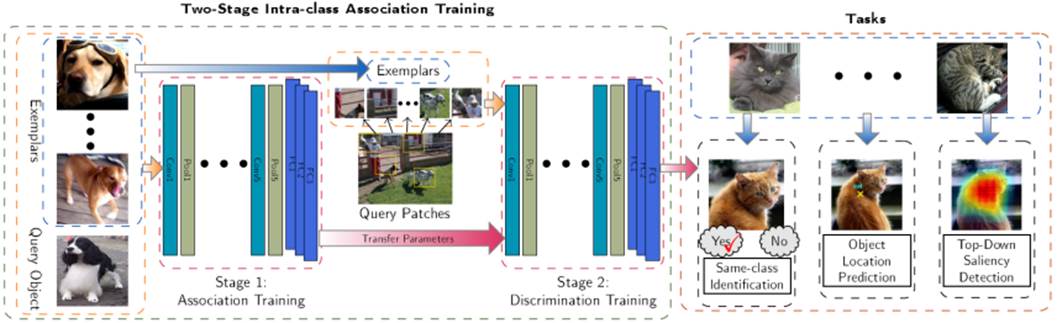
|
|
Input-Output: Given a number of exemplar
images containing a specific type of objects and another query image, our
network recognizes the common object type in the exemplar images and detect
it from the query image.
Abstract: Top-down saliency detection is
a knowledge-driven search task. While some previous methods aim to learn
this "knowledge" from category-specific data, others
transfer existing annotations in a large dataset through appearance
matching. In contrast, we propose in this paper a locate-by-exemplar strategy.
This approach is challenging, as we only use a few exemplars (up to 4) and
the appearances among the query object and the exemplars can be very
different. To address it, we design a two-stage deep model to learn the
intra-class association between the exemplars and query objects. The first
stage is for learning object-to-object association, and the second stage is
to learn background discrimination. Extensive experimental evaluations show
that the proposed method outperforms different baselines and the
category-specific models. In addition, we explore the influence of exemplar
properties, in terms of exemplar number and quality. Furthermore, we show
that the learned model is a universal model and offers great generalization
to unseen objects.
|
|
|
SuperCNN: A
Superpixelwise Convolution Neural Network for Salient Object Detection [paper]
Shengfeng
He, Rynson Lau, Wenxi Liu, Zhe Huang, and Qingxiong Yang
International
Journal of Computer Vision,
115(3):330-344, Dec. 2015
|
|

|
|
Input-Output: Given
an input image, our network detects the salient objects in it.
Abstract: Existing computational models
for salient object detection primarily rely on hand-crafted features, which
are only able to capture low-level contrast information. In this paper, we
learn the hierarchical contrast features by formulating salient object detection
as a binary labeling problem using deep learning techniques. A novel
superpixelwise convolutional neural network approach, called SuperCNN, is
proposed to learn the internal representations of saliency in an effi-
cient manner. In contrast to the classical convolutional networks, SuperCNN
has four main properties. First, the proposed method is able to learn the
hierarchical contrast features, as it is fed by two meaningful superpixel
sequences, which is much more effective for detecting salient regions than
feeding raw image pixels. Second, as SuperCNN recovers the contextual
information among superpixels, it enables large context to be involved in
the analysis efficiently. Third, benefiting from the superpixelwise
mechanism, the required number of predictions for a densely labeled map is
hugely reduced. Fourth, saliency can be detected independent of region size
by utilizing a multiscale network structure. Experiments show that SuperCNN
can robustly detect salient objects and outperforms the state-of-the-art
methods on three benchmark datasets.
|
|
|
Oriented Object
Proposals
[paper]
Shengfeng
He and Rynson Lau
Proc. IEEE ICCV, pp. 280-288, Dec. 2015
|
|

|
|
Input-Output: Given
an input image, our method outputs a list of oriented bounding boxes that
likely contain objects.
In
this paper, we propose a new approach to generate oriented object proposals
(OOPs) to reduce the detection error caused by various orientations of the
object. To this end, we propose to efficiently locate object regions
according to pixelwise object probability, rather than measuring the
objectness from a set of sampled windows. We formulate the proposal
generation problem as a generative probabilistic model such that object
proposals of different shapes (i.e., sizes and orientations) can be
produced by locating the local maximum likelihoods. The new approach has
three main advantages. First, it helps the object detector handle objects
of different orientations. Second, as the shapes of the proposals may vary
to fit the objects, the resulting proposals are tighter than the sampling
windows with fixed sizes. Third, it avoids massive window sampling, and
thereby reducing the number of proposals while maintaining a high recall.
Experiments on the PASCAL VOC 2007 dataset show that the proposed OOP
outperforms the stateof-the-art fast methods. Further experiments show that
the rotation invariant property helps a class-specific object detector
achieve better performance than the state-of-the-art proposal generation
methods in either object rotation scenarios or general scenarios.
Generating OOPs is very fast and takes only 0.5s per image.
|
|
|
Saliency-Guided
Color-to-Gray Conversion using Region-based Optimization [paper] [suppl]
[code] [demo] [CSDD Dataset] [Results on
CSDD]
[Result on
Cadik]
Hao
Du, Shengfeng He, Bin Sheng, Lizhaung Ma, and Rynson Lau
IEEE Trans. on
Image Processing,
24(1):434-443, Jan. 2015
|
|
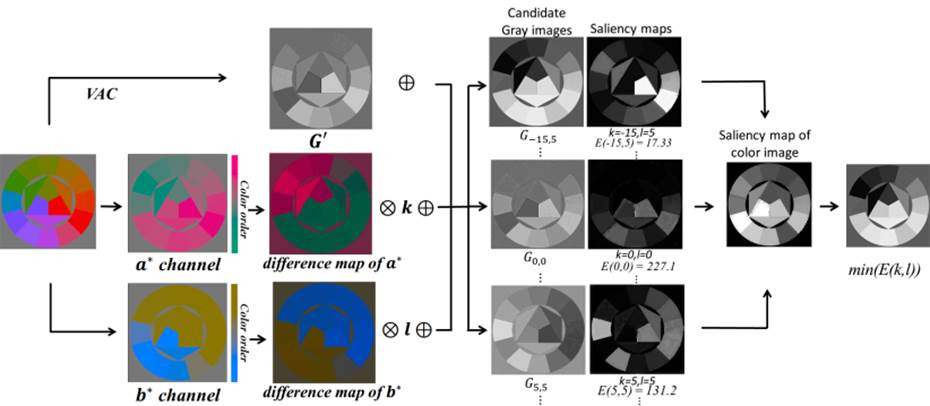
|
|
Input-Output: Given
an input color image, our method converts it into an output grayscale
image.
Abstract: Image decolorization is a
fundamental problem for many real world applications, including monochrome
printing and photograph rendering. In this paper, we propose a new
color-to-gray conversion method that is based on a region-based saliency
model. First, we construct a parametric color-to-gray mapping function
based on global color information as well as local contrast. Second, we
propose a region-based saliency model that computes visual contrast among
pixel regions. Third, we minimize the salience difference between the original
color image and the output grayscale image in order to preserve contrast
discrimination. To evaluate the performance of the proposed method in
preserving contrast in complex scenarios, we have constructed a new
decolorization dataset with 22 images, each of which contains
abundant colors and patterns. Extensive experimental evaluations on the
existing and the new datasets show that the proposed method outperforms the
state-of-the-art methods quantitatively and qualitatively.
|
|
Saliency Detection
with Flash and No-flash Image Pairs [paper] [suppl]
[dataset]
Shengfeng
He and Rynson Lau
Proc. ECCV, pp. 110-124, Sept. 2014.
|
|

|
|
Input-Output:
Given a pair
of flash/no-flash images, our method outputs the corresponding salient map.
Abstract: In this paper, we propose a
new saliency detection method using a pair of flash and no-flash images.
Our approach is inspired by two observations. First, only the foreground
objects are significantly brightened by the flash as they are relatively
nearer to the camera than the background. Second, the brightness variations
introduced by the flash provide hints to surface orientation changes.
Accordingly, the first observation is explored to form the background prior
to eliminate background distraction. The second observation provides a new
orientation cue to compute surface orientation contrast. These photometric
cues from the two observations are independent of visual attributes like
color, and they provide new and robust distinctiveness to support salient object
detection. The second observation further leads to the introduction of new
spatial priors to constrain the regions rendered salient to be compact both
in the image plane and in 3D space. We have constructed a new
flash/no-flash image dataset. Experiments on this dataset show that the
proposed method successfully identifies salient objects from various
challenging scenes that the state-of-the-art methods usually fail.
|
|