|
Low-light imaging is
often needed for various purposes, such as surveillance, photography and
autonomous driving. In particular for autonomous driving, day-time and
night-time each roughly contributes to 50% of the time over a year, and it is
equally important for computer vision techniques developed for day-time
scenes to work at night-time scenes. Unfortunately, low-light images
typically contain very dark regions, which may suffer from under-exposure
problems (i.e., their values are very close to zero), while night-time images
may suffer from both under-exposure as well as over-exposure problems (i.e.,
their values may be very close to either zero or one). Enhancing these images
or processing them with existing computer vision algorithms often do not
work.
In this project, we are
developing techniques to process low-light images. Our research is to address
this problem from two directions. The first is to consider how to enhance
these images to improve their visibility. The second is to investigate how to
improve existing computer vision algorithms for direct analyses of low-light
images.
|
|
Lighting up NeRF via
Unsupervised Decomposition and Enhancement [paper] [suppl] [code] [dataset]
Haoyuan
Wang, Xiaogang Xu, Ke Xu, and Rynson Lau
Proc. IEEE ICCV, Oct. 2023
|
|

A
comparison of the baseline model (LLE+NeRF), SOTA low light enhancement
models, and our model.
|
|
|
Input-Output: Given a set of 8-bit
low-light sRGB images, our network reconstructs a NeRF model of proper
lighting for rendering novel normal-light images.
Abstract. Neural Radiance
Field (NeRF) is a promising approach for synthesizing novel views, given a
set of images and the corresponding camera poses of a scene. However,
images photographed from a low-light scene can hardly be used to train a
NeRF model to produce high-quality results, due to their low pixel
intensities, heavy noise, and color distortion. Combining existing
low-light image enhancement methods with NeRF methods also does not work
well due to the view inconsistency caused by the individual 2D enhancement
process. In this paper, we propose a novel approach, called Low-Light NeRF
(or LLNeRF), to enhance the scene representation and synthesize
normal-light novel views directly from sRGB low-light images in an
unsupervised manner. The core of our approach is a decomposition of
radiance field learning, which allows us to enhance the illumination,
reduce noise and correct the distorted colors jointly with the NeRF
optimization process. Our method is able to produce novel view images with
proper lighting and vivid colors and details, given a collection of
camera-finished low dynamic range (8-bits/channel) images from a low-light
scene. Experiments demonstrate that our method outperforms existing
low-light enhancement methods and NeRF methods.
|
|
Local Color Distributions Prior
for Image Enhancement
[paper] [suppl] [video] [code] [dataset]
Haoyuan
Wang, Ke Xu, and Rynson Lau
Proc. ECCV, Oct. 2022
|
|
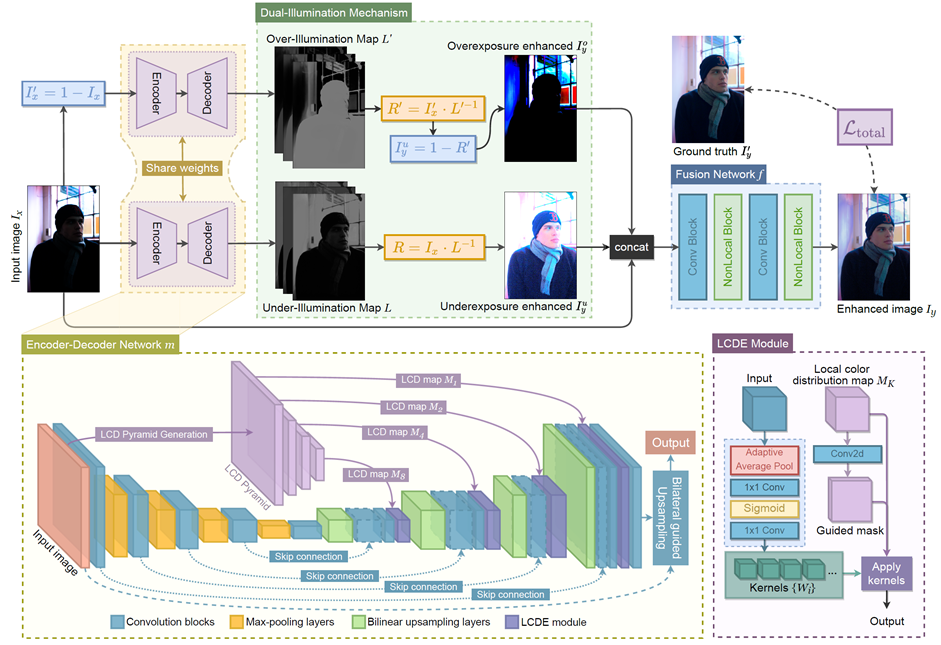
Overview of our proposed network. It leverages
the LCD pyramid with an encoder-decoder architecture for detecting the regions
with problematic exposures implicitly, and the dual-illumination learning
mechanism for enhancement of the over- and under-exposed regions.
|
|
|
Input-Output: Given an input image
with both over- and under-exposures, our network produces an output
enhancement image.
Abstract. Existing image
enhancement methods are typically designed to address either the over- or
under-exposure problem in the input image. When the illumination of the
input image contains both over- and under-exposure problems, these existing
methods may not work well. We observe from the image statistics that the
local color distributions (LCDs) of an image suffering from both problems
tend to vary across different regions of the image, depending on the local illuminations.
Based on this observation, we propose in this paper to exploit these LCDs
as a prior for locating and enhancing the two types of regions (i.e.,
over-/underexposed regions). First, we leverage the LCDs to represent these
regions, and propose a novel local color distribution embedded (LCDE)
module to formulate LCDs in multi-scales to model the correlations across different
regions. Second, we propose a dual-illumination learning mechanism to
enhance the two types of regions. Third, we construct a new dataset to
facilitate the learning process, by following the camera image signal
processing (ISP) pipeline to render standard RGB images with both
under-/over-exposures from raw data. Extensive experiments demonstrate that
the proposed method outperforms existing state-of-the-art methods
quantitatively and qualitatively.
|
|
Night-time Semantic
Segmentation with a Large Real Dataset [paper] [dataset
images] [dataset
labels] [reannotated val
set]
Xin
Tan, Ke Xu, Ying Cao, Yiheng Zhang, Lizhuang Ma, and Rynson Lau
IEEE Trans. on
Image Processing,
30: 9085-9098, Oct. 2021
|
|

Visual comparison of our results with those of
the state-of-the-art methods. Our advantages are highlighted by white boxes.
A few drawbacks of the other methods are marked by yellow boxes. All the
methods are trained on NightCity.
|
|
|
Input-Output: Given an input
night-time image, our network directly produces a semantic segmentation
map.
Abstract. Although huge progress
has been made on semantic segmentation in recent years, most existing works
assume that the input images are captured in day-time with good lighting
conditions. In this work, we aim to address the semantic segmentation problem
of night-time scenes, which has two main challenges: 1) labeled night-time
data are scarce, and 2) over- and under-exposures may co-occur in the input
night-time images and are not explicitly modeled in existing semantic
segmentation pipelines. To tackle the scarcity of night-time data, we
collect a novel labeled dataset (named NightCity) of 4,297 real nighttime
images with ground truth pixel-level semantic annotations. To our
knowledge, NightCity is the largest dataset for night-time semantic
segmentation. In addition, we also propose an exposure-aware framework to address
the night-time segmentation problem through augmenting the segmentation
process with explicitly learned exposure features. Extensive experiments
show that training on NightCity can significantly improve the performance
of night-time semantic segmentation and that our exposure-aware model
outperforms the state-of-the-art segmentation methods, yielding top performances
on our benchmark dataset.
|
|
Learning to Restore Low-light
Images via Decomposition-and-Enhancement [paper] [suppl] [model]
[dataset]
Ke
Xu, Xin Yang, Baocai Yin, and Rynson Lau
Proc. IEEE
CVPR,
June 2020
|
|

While existing methods ((c) to (j)) generally
fail to enhance the input noisy low-light image (a), our method produces
a sharper and clearer result with objects and details recovered (l).
|
|
|
Input-Output: Given an input practical
low-light image, which often comes with a significant amount of noise due
to the low signal-to-noise ratio, our network enhances its brightness while
at the same time suppressing its noise level, to produce an enhanced clear
image.
Abstract. Low-light images
typically suffer from two problems. First, they have low visibility (i.e.,
small pixel values). Second, noise becomes significant and disrupts the
image content, due to low signal-to-noise ratio. Most existing lowlight image
enhancement methods, however, learn from noise-negligible datasets. They
rely on users having good photographic skills in taking images with low
noise. Unfortunately, this is not the case for majority of the low-light images.
While concurrently enhancing a low-light image and removing its noise is
ill-posed, we observe that noise exhibits different levels of contrast in
different frequency layers, and it is much easier to detect noise in the
low-frequency layer than in the high one. Inspired by this observation, we
propose a frequency-based decomposition-and-enhancement model for low-light
image enhancement. Based on this model, we present a novel network that
first learns to recover image objects in the low-frequency layer and then
enhances high-frequency details based on the recovered image objects. In
addition, we have prepared a new low-light image dataset with real noise to
facilitate learning. Finally, we have conducted extensive experiments to show
that the proposed method outperforms state-of-the-art approaches in enhancing
practical noisy low-light images.
|
|
|
Image Correction
via Deep Reciprocating HDR Transformation [paper] [suppl] [code] [dataset]
Xin
Yang, Ke Xu, Yibing Song, Qiang Zhang, Xiaopeng Wei, and Rynson Lau
Proc.
IEEE CVPR,
June 2018
|

Image correction results on an underexposed
input. Existing LDR methods have the limitation in recovering the missing
details, as shown in (b)-(f). In comparison, we recover the missing LDR
details in the HDR domain and preserve them through tone mapping,
producing a more favorable result as shown in (g).
|
|
|
Input-Output: Given an input low-light
image, our network produces an enhanced image with lost details recovered.
Abstract: Image correction
aims to adjust an input image into a visually pleasing one. Existing
approaches are proposed mainly from the perspective of image pixel
manipulation. They are not effective to recover the details in the
under/over exposed regions. In this paper, we revisit the image formation
procedure and notice that the missing details in these regions exist in the
corresponding high dynamic range (HDR) data. These details are well
perceived by the human eyes but diminished in the low dynamic range (LDR) domain
because of the tone mapping process. Therefore, we formulate the image
correction task as an HDR transformation process and propose a novel
approach called Deep Reciprocating HDR Transformation (DRHT). Given an
input LDR image, we first reconstruct the missing details in the HDR
domain. We then perform tone mapping on the predicted HDR data to generate
the output LDR image with the recovered details. To this end, we propose a united
framework consisting of two CNNs for HDR reconstruction and tone mapping.
They are integrated end-to-end for joint training and prediction.
Experiments on the standard benchmarks demonstrate that the proposed method
performs favorably against state-of-the-art image correction methods.
|
|